[!quote] Stream 流 Stream 允许你对集合进行链式调用,进行各种操作【
过滤、映射、聚合 ……】javapublic interface Stream\<T> extends BaseStream<T,Stream\<T>>
- Stream 流的操作不会影响原集合,但是除非你修改了引用对象
- Stream 是延迟求值的 : 它只会计算有终结操作的 Stream,如果一个流没有终结操作,那么它的中间操作也不会执行
循环处理技术对比
- 数据 < 1 万 ,for 循环 > foreach / 增强 for / 迭代器 > Stream
- 1 万 < 数据量 < 100 万 ,Stream > foreach / 增强 for / 迭代器 > for
- 数据 > 100 万 ,parallelStream 最高
❤ 静态方法
iterate(流的初始值,针对于初始值的操作)iterate(流的初始值,符合条件,递增规则)
java
// 针对一个LocalDate,每次迭代都plusDays,然后最终限制7个元素
List<LocalDate> nowDateList = Stream.iterate(
LocalDate.now(),
date -> date.plusDays(1)
).limit(7).toList();
Stream.iterate(monthSize - 1, data -> data >= 0, data -> data - 1)concat()合并流
java
List<String> list = new ArrayList<>();
list.add("吴彦祖");
list.add("陈冠希");
list.add("黎明");
list.add("吴京");
Stream<String> s1 = list.stream().limit(2);
Stream<String> s2 = list.stream().skip(1);
Stream.concat(s1, s2)
.forEach(System.out::println); //合并a,b。然后输出
---
吴彦祖
陈冠希
陈冠希
黎明
吴京▶️ 生成操作
通过数据源【数组、集合、IO 通道、生成器……】生成流
集合生成流
- 直接用集合调用
stream()方法
java
List<String> list = new ArrayList<String>();
Stream<String> stringStream = list.stream();数组生成流
java
int[] numbers = {1, 2, 3, 4, 5};
IntStream stream = Arrays.stream(numbers);零散数据生成流
Stream.of()
java
public static void main(String[] args) {
String arr[] = {"greenteck", "wiggles", "hoan"};
Stream<String> ArrStream = Stream.of(arr);
}java
public static void main(String[] args) {
Stream<String> Stream = Stream.of("greenteck", "wiggles", "hoan");
}迭代器 iterate 生产流
iterate(初始值,条件,累加操作)
java
Stream<Integer> stream = Stream.iterate(1, n -> n < 10, n -> n * 2);
stream.forEach(System.out::print);
---
1248↔️ 中间操作
filter
filter 里传入一个 Predicate 接口,用于判断流中的元素是否符合条件,如果返回 True 则留下,如果是 False 则过滤掉
java
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("吴彦祖");
list.add("陈冠希");
list.add("黎明");
list.add("吴京");
// 生成 Stream 流
list.stream()
// 调用filter接口
.filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.startsWith("吴"); // 只有姓吴的可以留下
}
})
.filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.length() == 3; // 只有长度大于3可以留下
}
})
.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
}
吴彦祖limit,skip
limit(个数)获取流前面的 n 个元素skip(个数)跳过流前面的 n 个元素
java
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("吴彦祖");
list.add("陈冠希");
list.add("黎明");
list.add("吴京");
list.stream().limit(2).forEach(System.out::println);
System.out.println("----------");
list.stream().skip(1).forEach(System.out::println);
}
吴彦祖
陈冠希
----------
陈冠希
黎明
吴京distinct
distinct()去重
java
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("吴彦祖");
list.add("陈冠希");
list.add("黎明");
list.add("吴京");
Stream<String> s3 = list.stream().limit(2);
Stream<String> s4 = list.stream().skip(1);
Stream.concat(s3, s4)
.distinct().forEach(System.out::println); //去除重复
}
吴彦祖
陈冠希
黎明
吴京sorted
- 返回值为 0 ,排序位置保持不变
- 返回值 > 0,排序位置 o1 在后面
- 返回值 < 0,排序位置 o1 在前面
java
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(32);
list.add(1);
list.add(992);
list.add(33);
list.stream()
.sorted()
.forEach(System.out::println);
list.stream()
.sorted(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return 0;
}
}).forEach(System.out::println);
}
1
32
33
992
----------
32
1
992
33map,mapToInt
map对 Stream 中的每个元素应用一个函数,用这个函数的返回值替代原始元素,从而生成一个新的 Stream
对象::属性名把对象集合 -> 对象中的某个属性集合
java
// 将awardBO集合,转为awardBO的属性awardId的集合
List<Integer> awardIds = awardBOs.stream()
.map(AwardBO::getAwardId)
.toList();java
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("32");
list.add("1");
list.add("992");
list.add("33");
list.stream().map(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s) + 1;
}
}).forEach(System.out::println);
System.out.println("-----------------");
list.stream().mapToInt(new ToIntFunction<String>() {
@Override
public int applyAsInt(String value) {
return Integer.parseInt(value) + 2;
} //通过mapToInt可以将Stream转换为IntStream
}).forEach(System.out::println); //在IntStream里有一些对int的特有操作
}
33
2
993
34
-----------------
34
3
994
35flatMap
[!quote]
flatMap()flatMap可以把流压平
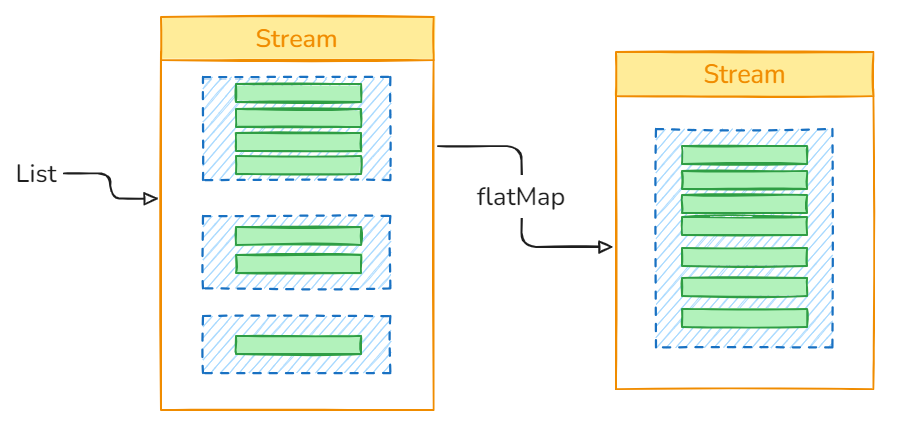
java
// 使用 map,你要手动过滤空值
List<String> filteredList = list.stream()
.map(o -> o.isPresent() ? o.get() : null)
.filter(Objects::nonNull)
.collect(Collectors.toList());
// 使用 flatMap,在将元素转换成流时,空值会被转为空流,空流在合并时会自动消失
List<String> filteredListJava9 = list.stream()
.flatMap(Optional::stream) // 在将所有的optional转为流后,将所有的流合起来
.collect(Collectors.toList());
// departmentIds 中的 value 是逗号分隔的字符串
departmentIds.keySet().stream()
.map(departmentIds::get)
.flatMap(item -> Arrays.stream(item.split(",")))
.toList();peek
peek 的设计初衷就是用于调试或观察流中元素的状态,不应该对元素做修改。比如我想要查看流中某个过程的元素是什么,我就可以 peek 打印一下看一下,而不是 foreach 直接关闭流,也就是非终结的 foreach 操作
java
// 使用 peek 来调试流中的元素
List<Integer> processedNumbers = Arrays.asList(1, 2, 3, 4, 5).stream()
.filter(n -> n % 2 == 0)
.peek(n -> System.out.println("Filtered even number: " + n)) // 调试输出
.map(n -> n * n)
.peek(n -> System.out.println("Squared number: " + n)) // 调试输出
.toList();处理有序 Stream
takeWhile
takeWhile 从一个有序的 Stream 中取出满足条件的所有元素,一旦遇到不满足条件的元素,就会停止处理后续元素
java
Stream.of("a", "b", "c", "de", "f")
.takeWhile(s -> s.length() == 1)
.forEach(System.out::print);
---
abcdropWhile
从一个有序的 Stream 中丢弃满足条件的所有元素,一旦遇到不满足条件的元素,就会开始处理后续元素
java
Stream.of("a", "b", "c", "de", "f")
.dropWhile(s -> s.length() == 1)
.forEach(System.out::print);
---
def🔚 终结操作
如果一个流不进行终结操作,则这个流在执行时,不会执行中间操作,相当于这个流从来没有执行过 :
java
// 这个程序看似会将数据add进list中,但是由于这个流操作没有终结操作,peek操作压根不会执行
List\<JSONObject> list = new ArrayList<>();
sbdqas.queryAll(qs).stream()
.peek(a -> {
Map<String, String> contentMap = a.toContentMap();
contentMap.put("t", AmountUtil.c(contentMap.get("t")));
list.add(new JSONObject(contentMap));
});一个流使用终结操作后,就无法再进行操作了,这是流的最后一个操作
void forEach(Consumer action)对该流的每个元素执行操作long count()返回该流中的元素个数R collect(Collector collector)按照 collector 的要求,把元素收集到集合中
forEach
java
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("32");
list.add("1");
list.add("992");
list.add("33");
list.stream().forEach(new Consumer<String>() {
@Override
public void accept(String s) {
StringBuilder sb = new StringBuilder(s);
sb.append(1);
System.out.println(sb.toString());
}
});
}
321
11
9921
331java
// 简化版
list.stream().forEach(s -> {
StringBuilder sb = new StringBuilder(s);
sb.append(1);
System.out.println(sb.toString());
});min,max
min(比较器)是返回一个比较器中最左边的元素,因为比较器默认左小右大max(比较器)是返回一个比较器中最右边的元素,因为比较器默认左小右大
java
Optional<JSONObject> first = referenceRateData.stream()
.map(AbstractStandingBookData::getContent)
.max((o1, o2) -> {
LocalDateTime timeOne = LocalDateTimeUtil.parse(o1.getString("lastModDateTime"), DatePattern.NORM_DATETIME_PATTERN);
LocalDateTime timeTwo = LocalDateTimeUtil.parse(o2.getString("lastModDateTime"), DatePattern.NORM_DATETIME_PATTERN);
if (timeOne.isEqual(timeTwo)) {
return 0;
} else if (timeOne.isBefore(timeTwo)) {
return -1;
} else {
return 1;
}
});findFirst
Optional findFirst获取流中的第一个元素,并返回 Optional 对象get()获取到 Optional 对象的值,也就是 Stream 流中的元素
[!hint] 获得 Stream 流中的最后一个元素:
- 先 skip (长度 - 1) 个元素
- 再 findFirst
count
java
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("32");
list.add("1");
list.add("992");
list.add("33");
System.out.println(list.stream().count());
}
4reduce
reduce(累加逻辑)reduce(初始值,累加逻辑)
java
List<String> props = List.of("profile=native", "debug=true", "logging=warn", "interval=500");
Map<String, String> map = props.stream()
// 把k=v转换为Map[k]=v:
.map(kv -> {
String[] ss = kv.split("\\=", 2);
return Map.of(ss[0], ss[1]);
})
// 把所有Map聚合到一个Map:
.reduce(new HashMap<String, String>(), (m, kv) -> {
m.putAll(kv);
return m;
});reduce(初始值,累加逻辑,合并器逻辑)合并器指定了,在并行流中,出现两个累加器时应该怎么处理
java
ObjectNode node = springTreeList.stream()
.reduce(new ObjectMapper().createObjectNode(),
(acc, item) -> {
acc.putPOJO("node", item);
return acc;
},
// 生成的多个objectNode,只保留第一个
(acc1, acc2) -> acc1
);anyMatch,allMatch,noneMatch
anyMatch判断的条件里,任意一个元素 true,返回 trueallMatch判断条件里的元素,所有的元素都 true,返回 truenoneMatch判断条件里的元素,所有的都 false,返回 true
java
List<String> words = List.of("apple", "banana", "cherry");
boolean anyMatch = words.stream()
.anyMatch(word -> word.equals("apple"));
boolean allMatch = words.stream()
.allMatch(word -> word.equals("apple"));
boolean noneMatch = words.stream()
.noneMatch(word -> word.equals("pear"));
System.out.println(anyMatch);
System.out.println(allMatch);
System.out.println(noneMatch);
---
true
false
truecollect
toList
collect(……)Collectors.toList()将 Stream 流收集成 List 集合
toList()将 Stream 流收集成不可变的 List 集合
java
public static void main(String[] args) {
List<Integer> list = List.of(32, 1, 992, 33);
List<Integer> collect = list.stream().filter((Integer i) -> {
return i > 1;
}).collect(Collectors.toList());
System.out.println(collect);
}
[32, 992, 33]toMap
Collectors.toMap(new Function<>(){} ,new Function<>(){})将 Stream 流收集成 Map 集合
java
String arr[] = {"陈冠希,14", "吴彦祖,66", "刘德华,2"};
Map<String, Integer> collect = Stream.of(arr)
.filter(s -> {
// 过滤掉年龄大于2的,并生成流
return Integer.parseInt(s.split(",")[1]) > 2;
})
.collect(Collectors.toMap(
s -> s.split(",")[0], // keyMapper: 分割字符串并取第一部分作为键
s -> Integer.parseInt(s.split(",")[1]) // valueMapper: 分割字符串并解析第二部分为整数作为值
));
System.out.println(collect);
{陈冠希=14, 吴彦祖=66}Collectors.toMap(lambda ,lambda, 保留哪个)将 Stream 流收集成 Map 集合,如果出现重复键,保留哪个
java
// 这里是为了去除重复
maps.stream()
.peek(item -> { …… })
.collect(Collectors.toMap(
item -> item.get("department_name"),
item -> item,
(existing, replace) -> existing
))
.values()
.stream()
.toList();joining
Collectors.joining(间隔字符,开始字符,结束字符)将字符串类型的 Stream 收集成一个 String
java
List<String> words = List.of("apple", "banana", "cherry", "date");
String result = words.stream()
.collect(Collectors.joining(", ", "[", "]"));
System.out.println(result);
---
[apple, banana, cherry, date]groupingBy
groupingBy(分组条件)根据某个属性,对流中的元素进行分组,生成一个 Map
java
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 20),
new Person("Charlie", 30),
new Person("David", 20)
);
// 将根据年龄进行分组
Map<Integer, List<Person>> peopleByAge = people.stream()
.collect(Collectors.groupingBy(Person::getAge));groupingBy(分组条件,对分组后的元素处理的操作)根据某个属性,对流中的元素进行分组,再对分组后的元素进行操作,生成一个 Map
java
// 根据年龄进行分组,对分组后的元素进行计数
Map<Integer, Long> countByAge = people.stream()
.collect(Collectors.groupingBy(Person::getAge, Collectors.counting()));
countByAge.forEach((age, count) -> {
System.out.println("Age: " + age);
System.out.println("Count: " + count);
System.out.println();
});
---
Age: 20
Count: 2
Age: 30
Count: 2java
// 根据年龄进行分组,对分组后的元素进行拿取属性,再组成集合
Map<Integer, List<String>> collect3 = people.stream()
.collect(Collectors.groupingBy(Person::getAge, Collectors.mapping(Person::getName, Collectors.toList())));
collect3.forEach((age, names) -> {
System.out.println("Age: " + age);
System.out.println("Name: " + names);
System.out.println();
});
---
Age: 20
Name: [Bob, David]
Age: 30
Name: [Alice, Charlie]mapping
Collectors.mapping就是高级版的.map().toList(),主要用在Collectors.groupingBy()里面,在分组时,提取某个属性收集
java
List<Order> orders = List.of(
new Order(1L, 1L, 1L, "order1", "100"),
new Order(2L, 2L, 1L, "order2", "200"),
new Order(3L, 3L, 2L, "order3", "300")
);
Map<Long, List<String>> collect = orders.stream()
.collect(Collectors.groupingBy(
Order::getCustomerNo,
Collectors.mapping(Order::getOrderName, Collectors.toList()))
);
System.out.println(collect);
---
{1=[order1, order2], 2=[order3]}❤️ 数值流
在处理数值时,比如流元素的平均数,累加 …… ,基础对象流 Stream<T> 并不方便,所以引入了数值流【IntStream ,DoubleStream ,LongStream】
常见的数值流 :
mapToInt()mapToLong()mapToDouble返回一个专门用于处理double的DoubleStream数值流mapToObj(操作)将数值流映射回一般的对象流Stream<T>
数值流的方法 :
sum()返回流中所有元素的和count()返回流中所有元素的数量average()返回流中所有元素的平均值min()返回流中的最小值max()返回流中的最大值boxed()将数值流转为对应的Stream<T>
java
double totalPayable = content.stream()
.mapToDouble(item -> item.getDouble("totalPayable"))
.sum();❤ 并行流
[!quote] 并行流 并行流 是指将数据分成多个部分,然后并行处理流中的每个元素
- 优点
- 利用了多核处理器的优势
- 对海量数据的处理效率更高
- 缺点
- 但是由于是多线程的,要考虑并发问题
- 如果是少量数据,使用并行流反而没优势,因为并行流要创建线程,销毁线程,这些都要时间
- 并行流处理流元素是无序的
parallelStream()将集合转为并行流parallel()将顺序流转为并行流
java
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 创建并行流
Stream<Integer> parallelStream = numbers.parallelStream();❤️ 注意
- Stream 流最好是无状态的,
即 Stream 的每一步操作不依赖外部的状态,也不会改变外部状态 - 在 Lambda 表达式中只能引用
final或effectively final的局部变量,所以 Stream 流也不例外