[!hint] 为什么要引入集合 ? 因为数组的长度无法改变,所以我们用到了集合
❤ Collection
public interface Collection<E> extends Iterable<E>add("hello");添加元素remove("hello");删除元素clear();清空集合中的元素- 判断
contains("hello");判断集合中是否有指定元素containAll(集合B)判断集合 B 的元素,集合 A 里是否都有isEmpty();判断集合是否为空
size();判断集合中元素的个数- 交集,差集
Boolean retainAll(集合2)返回集合和集合 2 的交集,如果集合因调用而更改,则返回 trueremoveAll(集合2)集合 2 中的元素,集合中都没有,如果集合因调用而更改,则返回 true
[!hint] 创建 Collection 对象并使用
javapublic class collection { public static void main(String[] args) { Collection\<String> c1 = new ArrayList\<>(); String s1 = "绿坦"; String s2 = "kite"; c1.add(s1); c1.add(s2); System.out.println(c1); } } --- [绿坦, kite]
[!hint] Collection 集合的遍历
[!quote] Iterator 迭代器
next()返回迭代中的下一个元素hasNext()判断next()之后是否还有元素javapublic static void main(String[] args) { Collection\<String> c1 = new ArrayList<>(); String s1 = "绿坦"; String s2 = "kite"; c1.add(s1); c1.add(s2); Iterator\<String> i1 = c1.iterator(); while (i1.hasNext()) { String s = i1.next(); System.out.println(s); } } -- 绿坦 kite[!quote] 增强 for【原理也是一个迭代器】
javaint arr[] = {1, 2, 3}; for (int i : arr) { System.out.println(i); } -- 1 2 3
💛 List
[!quote] List List 集合的特点就是索引
- 静态方法
- 【增】
List.of(……)向集合中一次性添加元素,生成一个不可变集合(并且集合中不允许有 null 值)
- 【增】
- 非静态方法
- 【增】
add(索引,数值);在集合中指定位置添加元素
- 【删】
remove(值)删除指定值,如果没有返回 null
- 【改】
set(索引,数值);修改指定索引处的元素List subList(索引1,索引2)截取列表中的一部分,生成新集合,不影响原集合
- 【查】
get(索引);返回指定元素
- 【增】
List<String> list = new ArrayList<>();
list.add(0, "李白");
list.set(0, "杜甫");
String s1 = list.get(0);
System.out.println(s1);
---
杜甫[!quote] ListIterator 迭代器 ListIterator 可以实现双向遍历
public interface ListIterator\<E> extends Iterator\<E>
- 从后往前遍历
hasPrevious()判断previous()是否遍历完成previous()从后向前一个一个遍历javapublic static void main(String[] args) { List\<String> list = new ArrayList<>(); list.add("李白"); list.add("杜甫"); list.add("王维"); ListIterator lstitrt = list.listIterator(); // 从前往后遍历 while (lstitrt.hasNext()) { System.out.print(lstitrt.next()); } System.out.println(""); System.out.println(" "); // 从后往前遍历 while (lstitrt.hasPrevious()) { System.out.print(lstitrt.previous()); } } —— 李白杜甫王维 王维杜甫李白javaList\<String> list = new ArrayList<>(); list.add("李白"); list.add("杜甫"); list.add("王维"); ListIterator lstitrt = list.listIterator(); while (lstitrt.hasPrevious()) { System.out.print(lstitrt.previous()); } —— NULL如果不使用 next() 方法,直接使用 previous() 方法,会导致什么也不打印
因为实现遍历的背后原理是指针,没有向后遍历的基础,向前遍历指针指向集合的最开始,所以不会有结果
如果一定要在迭代时改变集合元素,请使用 ListIterator 的 `add` 方法
以下代码会报出异常,这是由于在迭代时使用 List 集合的 add 方法改变集合:
public static void main(String[] args) {
List\<String> list = new ArrayList<>();
list.add("李白");
list.add("杜甫");
ListIterator\<String> lstitrt = list.listIterator();
while (lstitrt.hasNext()) {
String s = lstitrt.next();
if (s.equals("杜甫")) {
list.add("王安石");
}
}
}
——
Exception in thread "main" java.util.ConcurrentModificationException💙 ArrayList
[!quote]
ArrayListArrayList 是基于动态数组实现的 List
💙 LinkedList
[!quote]
LinkedListLinkedList 基于双向链表实现的 List
- 增
addFirst(e)在该列表的开头插入 e 元素addLast(e)在该列表的末尾插入 e 元素
- 删
removeFirst()删除并返回第一个元素removeLast()删除并返回最后一个元素
- 查
getFirst()返回此列表中的第一个元素getLast()返回此列表中的最后一个元素
💙 Vector
[!quote] Vector Vector 是一个线程安全集合,不过我们需要线程安全时也不常使用它,我们一般使用
synchronizedList()方法public class Vector\<E> extends AbstractList\<E> implements List\<E>, RandomAccess, Cloneable, Serializable
- 使用
synchronizedList()方法
List<String> list=Collections.synchronizedList(new ArrayList<>());💛 Set
[!quote] Set
- 不能有重复元素
- 可以有
NULL值- 无序
- 没有索引
public interface Set\<E> extends Collection\<E>
- 静态方法
Set.of(……)生成一个不可变 Set 集合
- 非静态方法
- 【增】
add(E e)添加元素,如果元素重复,则忽略该操作
- 【删】
remove(E e)删除元素clear()清空集合
- 【查】
size()返回集合的元素数contains(E e)判断集合是否有指定元素
- 【增】
💙 HashSet
[!quote]
HashSetHashSet的底层数据结构是哈希表
Hash 容器 :Hash 容器可以根据 hashcode 定位到相应的对象【即 】,Hash 容器有:HashSet,HashMap,HashTable,ConcurrentHashMaphashcode 不同,两个对象不同
哈希值 hashcode :每一个对象都有属于自己的 hashcode ,是用于区分不同对象的整型变量
- 默认由 Object 类中的本地方法
hashcode()生成,所以它不是内存地址 - 如果两个对象的
equals()方法返回相同的值,那这两个对象的 hashcode 必须相同,要不然 HashMap 怎么跟据 key 找值 - 但是两个对象的 hashcode 相同,不一定相等,也就是哈希冲突,需要通过
equals()做进一步判断
哈希冲突 :不同的输入值经过 hashcode() 处理后产生了相同的 hashcode【哈希值】,哈希冲突是不可避免的,因为哈希函数将无限的输入映射到有限的输出
// "重地" 的 Unicode 编码是 37325 和 22320,计算哈希码得到 37325 * 31 + 22320 = 1179395。
// "通话" 的 Unicode 编码是 36890 和 35805,计算哈希码得到 36890 * 31 + 35805 = 1179395。
System.out.println("重地".hashCode()); //1179395
System.out.println("通话".hashCode()); //1179395[!hint]+ 为什么 HashSet 可以保证元素的唯一性 ?
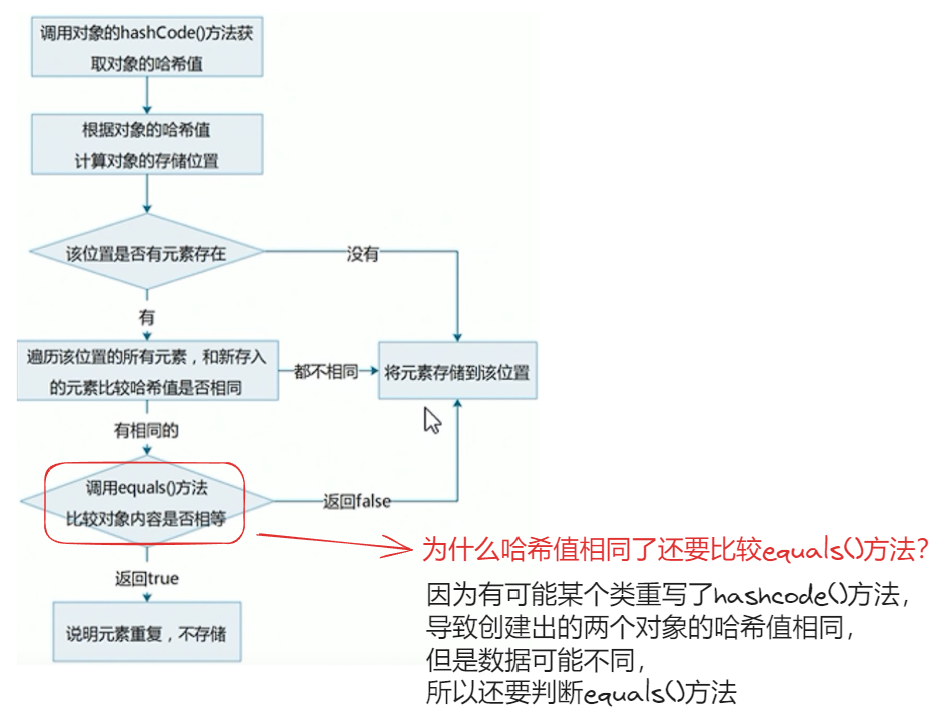
[!hint]+ 比较对象时,需要重写
hashcode()和equals()方法
- 没有重写时
javapublic static void main(String[] args) { HashSet\<students> hs = new HashSet\<students>(); students s1 = new students(12, "吴彦祖"); students s2 = new students(12, "陈冠希"); students s3 = new students(12, "吴彦祖"); students s4 = new students(23, "刘德华"); hs.add(s1); hs.add(s2); hs.add(s3); hs.add(s4); for (students s : hs) { System.out.println(s.getAge() + s.getName()); } } 23刘德华 12吴彦祖 12吴彦祖 //打印了两个吴彦祖,说明哈希表认为s1和s3是不同对象 12陈冠希
- 重写后
java@Data @NoArgsConstructor @AllArgsConstructor public class students { private int age; private String name; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; students students = (students) o; if (age != students.age) return false; return name != null ? name.equals(students.name) : students.name == null; } @Override public int hashCode() { int result = age; result = 31 * result + (name != null ? name.hashCode() : 0); return result; } } // 测试类 public class collection { public static void main(String[] args) { HashSet\<students> hs = new HashSet\<students>(); students s1 = new students(12, "吴彦祖"); students s2 = new students(12, "陈冠希"); students s3 = new students(12, "吴彦祖"); students s4 = new students(23, "刘德华"); hs.add(s1); hs.add(s2); hs.add(s3); hs.add(s4); for (students s : hs) { System.out.println(s.getAge() + s.getName()); } } } 12吴彦祖 12陈冠希 23刘德华
💚 LinkedHashSet
[!quote] LinkedHashSet LinkedHashSet 底层是哈希表和链表,可以预测迭代顺序
public class LinkedHashSet\<E> extends HashSet\<E> implements Set\<E>, Cloneable, Serializable
💙 TreeSet
[!quote] TreeSet TreeSet 是一种有序集合,要求集合中的元素必须是可比较的,所以 TreeSet 中的元素必须实现 Comparable 接口或者在创建 TreeSet 时提供一个 Comparator 比较器对象
public class TreeSet\<E> extends AbstractSet\<E> implements NavigableSet\<E>,Cloneable,Serializable
TreeSet()无参构造,元素按照自然排序TreeSet(Comparator c)带参构造,根据指定的比较器进行排序
实现 Comparable 接口的无参构造
- 元素为 Integerjava
public static void main(String[] args) { TreeSet<Integer> ts = new TreeSet<Integer>(); //这里的元素用了Integer,而不是int //是因为Integer实现了Comparable接口,int没有 ts.add(190); ts.add(33); ts.add(77); for (Integer i : ts) { System.out.println(i); } } 33 77 190 - 元素为 students,return 0;java
public class students implements Comparable<students>{ private int age; private String name; public students(int age, String name) { this.age = age; this.name = name; } public int getAge() {return age;} public void setAge(int age) {this.age = age;} public String getName() {return name;} public void setName(String name) {this.name = name;} @Override public int compareTo(students o) { return 0; //首先添加s1,添加s2的时候返回0(表示s2的元素和s1相同),不存储 } }javapublic class collection { public static void main(String[] args) { TreeSet<students> ts = new TreeSet<students>(); students s1 = new students(12, "吴彦祖"); students s2 = new students(23, "陈冠希"); students s3 = new students(42, "刘德华"); students s4 = new students(12, "吴彦祖"); ts.add(s1); ts.add(s2); ts.add(s3); ts.add(s4); for (students s : ts) { System.out.println(s.getAge() + s.getName()); } } } 12吴彦祖 - 元素为 students,return 1;java
public class students implements Comparable<students>{ private int age; private String name; public students(int age, String name) { this.age = age; this.name = name; } public int getAge() {return age;} public void setAge(int age) {this.age = age;} public String getName() {return name;} public void setName(String name) {this.name = name;} @Override public int compareTo(students o) { return 1; //首先存s1,存s2时返回1(表示s2大于s1),s2存在s1之后 } } 12吴彦祖 23陈冠希 42刘德华 12吴彦祖 - 元素是 students,灵活 return;java
public class students implements Comparable<students>{ private int age; private String name; public students(int age, String name) { this.age = age; this.name = name; } public int getAge() {return age;} public void setAge(int age) {this.age = age;} public String getName() {return name;} public void setName(String name) {this.name = name;} @Override public int compareTo(students o) { int i = this.age - o.age; return i; } } 12吴彦祖 23陈冠希 42刘德华
- 元素为 Integer
提供 Comparator 比较器对象的带参构造
javapublic class collection { public static void main(String[] args) { TreeSet<students> ts = new TreeSet<students>(new Comparator<students>() { @Override public int compare(students o1, students o2) { int sum = o1.getAge() - o2.getAge(); return sum; } }); //此处为匿名内部类,是Comparator接口的实现类对象 students s1 = new students(12, "吴彦祖"); students s2 = new students(23, "陈冠希"); students s3 = new students(42, "刘德华"); students s4 = new students(12, "吴彦祖"); ts.add(s1); ts.add(s2); ts.add(s3); ts.add(s4); for (students s : ts) { System.out.println(s.getAge() + s.getName()); } } } 12吴彦祖 23陈冠希 42刘德华
❤ Map
[!quote] Map Map 集合 不能有重复的 key,每个 key 最多映射到一个值
- 给 Map 添加键值对时,key 可以是 null,不会报错,但是最好不要
静态方法 :
- 【增】
Map.of(……)生成一个不可变的 map 集合【最多只能有 10 个键值对】Map.ofEntries传递无限个 Entry 对象
Map<String, Integer> map = Map.of("one", 1, "two", 2, "three", 3);非静态方法 :
- 【增】
put(K key,V value)插入元素,如果 key 存在,则覆盖putAll(Map集合)将另一个 map 集合添加到当前集合,如果 key 重复则覆盖putIfAbsent(K key, V value)如果 key 存在则不做任何处理,否则插入merge(key, value, 冲突处理方法)添加键值对,如果集合中存在相同 key,则会覆盖旧值,也可以自定义冲突处理方法T compute(Key, BiFunction函数式接口)无论 key 是否存在,都对该 key 的 value 进行计算- 如果这个 key 存在,则将 Key,和该值作为函数式接口的入参;
- 如果这个 key 不存在,则将 Key,和 null 值作为函数式接口的入参;
T computeIfAbsent(Key, Function函数式接口)只有当指定的键不存在时,才会执行函数式接口生成新的值T computeIfPresent(Key, BiFunction函数式接口)只有当指定的键存在时,才会执行函数式接口生成新的值。BiFunction 返回 null,则删除该键值对;BiFunction 返回 T,则将该键的值设为 T
- 【删】
remove(Object key)根据键删除键值对元素remove(key, value)只有当键值对条件都满足时,才删除clear()移除所有键值对元素
- 【查】
size()返回集合的长度get(Object key)根据键获取值getOrDefault(key, 默认值)如果找不到键值对,则返回默认值keySet()返回一个所有键的 Set 集合values()返回一个所有值的 Collection 集合entrySet()返回一个 Set 集合 Set<Map.Entry<String, Integer>>,其中每个Map.Entry表示一个键值对foreach((key, value) -> {……})Java 8 新增的遍历方法- 判断
boolean containsKey(Object key)判断集合是否包含指定的键boolean containsValue(Object value)判断集合是否包含指定的值boolean isEmpty()判断集合是否为空
[!quote]
Map.Entry<K,V>
getKey()返回 KgetValue()返回 V
Map<Integer, String> m = new HashMap<Integer, String>();
m.put(12, "吴彦祖");
m.put(23, "彭于晏");
m.put(12, "郭富城");
System.out.println(m.get(12));
System.out.println(m.get(34));
System.out.println(m.keySet());
System.out.println(m.values());
System.out.println(m.entrySet());
---
郭富城
null
[23, 12]
[彭于晏, 郭富城]
[23=彭于晏, 12=郭富城]compute
Map<String, Integer> map = new HashMap<>();
map.put("apple", 2);
// 无论键 "apple" 是否存在,都会对它重新计算
map.compute(
"apple",
(key, value) -> value == null ? 1 : value + 3
);
System.out.println(map.get("apple")); // 输出 5computeIfAbsent :
Map<String, List<Integer>> map = new HashMap<>();
map.put("a", new ArrayList<>(List.of(1, 2, 3)));
// 返回的集合的引用,所以直接add,可以影响原map
map.computeIfAbsent("a", k -> new ArrayList<>()).add(5);
---
[1, 2, 3, 5]💛 HashMap
HashMap<Integer, String> m = new HashMap<Integer, String>();
m.put(12, "吴彦祖");
m.put(23, "彭于晏");
m.put(34, "郭富城");
System.out.println(m);
{34=郭富城, 23=彭于晏, 12=吴彦祖}NOTE
关于 HashMap 的实现,JDK 8 和以前的版本有着很大的不同。当多个 Entry 被 Hash 到同一个数组下标位置时,为了提升插入和查找的效率,HashMap 会把 Entry 的链表转化为红黑树。
💙 LinkedHashMap
LinkedHashMap 为键值对维护了一张链表,记录了从最旧到最新的键值对
LinkedHashMap()新旧策略是按照插入的顺序排LinkedHashMap(初始容量,扩容因子,排序策略)初始容量一般为 16,扩容因子一般为 0.75- 排序策略
- true 访问顺序
- false 插入顺序
- 排序策略
💛 WeakHashMap
WeakHashMap 是弱引用 HashMap,如果该集合中的 key 不再被引用了,再下一次垃圾回收时,将会删除该键值对
构造函数 :
WeakHashMap()WeakHashMap(Map集合)将一个 Map 集合转成 WeakHashMap
💛 TreeMap
[!quote] TreeMap TreeMap 可以对 key 进行排序
javapublic class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>,Cloneable,Serializable
💛 线程安全集合
[!quote] 内部同步 和 外部同步
- 内部同步:在类或对象的实现内部进行的同步。通常,这是通过在方法上使用
synchronized关键字或者在代码块上使用synchronized锁来实现的
- 使用简单,不需要编写额外的同步代码
- 由于方法都被加了
synchronized,会导致性能损失- 外部同步:使用者需要自己管理对共享资源的访问,以保证线程安全
- 灵活性高,可以更加细粒度
- 使用复杂,容易出错
提供线程安全的方法 :
HashTable内部同步,不推荐Collections.synchronizedMap()外部同步,不推荐- 每次对 Map 的操作都需要同步,这会导致显著的性能开销
- 提供的是粗粒度的锁,任何时候只有一个线程可以访问 Map 的任何部分
ConcurrentHashMap特殊的内部同步,推荐
💙 HashTable
[!quote]
HashTable
HashTable不允许键和值为 null- 迭代器是弱一致的
💙 Collections.synchronizedMap
Map<Object,Object> map=Collections.synchronizedMap(new HashMap<>());
// 现在这个map集合就是线程安全集合了💙 ConcurrentHashMap
[!quote]
ConcurrentHashMapConcurrentHashMap中用的是分段锁【将数据分成多个段,每个段可以独立地被锁定,不同的线程可以同时访问不同段的数据,从而提高了并发性能】
- 由于是分段锁,细粒度更高,提高了并行度
- 由于是内部同步,使用起来就像使用
HashMap一样,简单方便- 性能高 :无锁设计
- 迭代器是弱一致的 :迭代器在迭代过程中可以容忍集合的并发修改【
不会抛异常】,但不会保证迭代器能够实时反映这些修改ConcurrentHashMap也允许键和值为 null
❤ Collections 工具
public class Collections
extends Object- 【排序】
sort()将指定的列表升序排列reverse()反转指定列表中的元素顺序shuffle()把集合里的元素顺序重新随机排列
- 【空集合】
emptyMap()返回一个不可变的空 Map
public static void main(String[] args) {
List list = new ArrayList();
list.add(30);
list.add(10);
list.add(100);
list.add(70);
System.out.println(list);
Collections.sort(list);
System.out.println(list);
Collections.reverse(list);
System.out.println(list);
Collections.shuffle(list);
System.out.println(list);
}
[30, 10, 100, 70]
[10, 30, 70, 100]
[100, 70, 30, 10]
[30, 70, 10, 100]