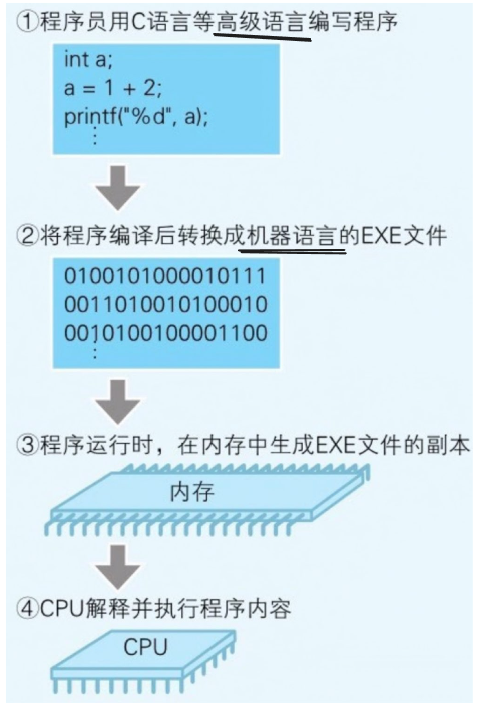
程序
程序 = 指令 + 数据 System.out.println(s); 这个程序中 System.out.println 是指令,s 是数据
程序运行的大体流程
调用函数的执行流程

- 入栈 :call 指令会把调用函数后要执行的指令地址(0154)存储在名为”栈“的主存内
- 出栈:return 指令的功能是把保存在栈中的地址设定到程序计数器中
加载到内存中的程序
当程序加载到内存后,会额外生成两个组,那就是栈和堆,栈中的代码,是由编译器自动生成的,因此不需要程序员得参与。但是堆的内存空间,则要根据程序员编写的程序,来明确进行申请分配或释放 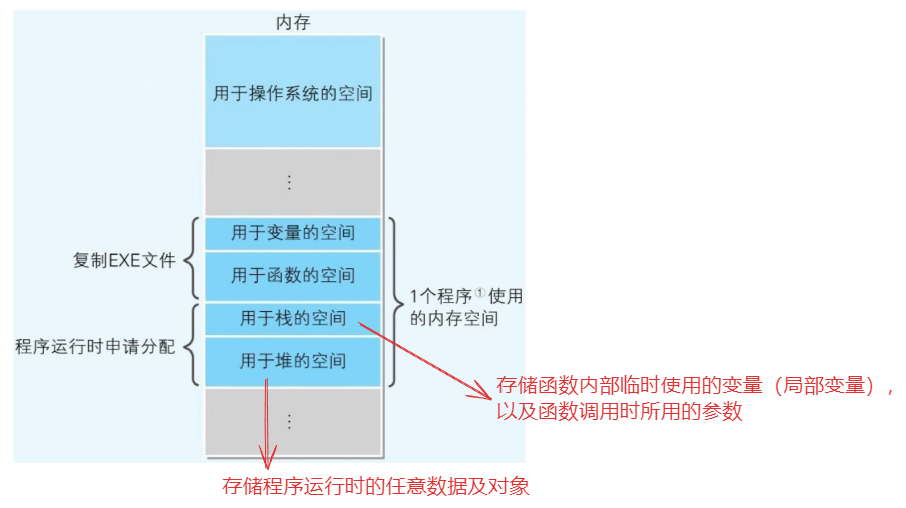
可执行文件的生成流程
- 本地代码:由一系列机器语言指令组成的二进制代码
- 链接:链接器可以指定库文件,指定之后可以把从中需要的目标文件抽取出来,然后和其他的目标文件结合生成
.exe

BIOS
- 在哪里 :BIOS 存储在 ROM 中
- 作用:BIOS 除了键盘,磁盘,显卡等基本控制程序外,还有启动引导程序的功能(引导程序:存储在启动驱动器起始区域的小程序,可以把硬盘等记录的 OS 加载到内存中运行)
- 工作流程 :开机后,BIOS 会确认硬件是否正常运行,没有问题的话就会启动引导程序,引导程序启动 OS,OS 启动应用程序
汇编与编译
汇编:汇编语言编写的程序转化成机器语言程序 反汇编:机器语言程序转化成汇编语言程序
编译:将使用高级语言编写的程序转换成机器语言的过程 反编译:将二进制代码转换为高级语言代码的过程
编译的特点
一行 C 语言程序在编译后通常会变成多行机器语言
反编译,反汇编的难度
本地代码变换成高级语言源代码的反编译,要比反汇编困难。 因为在编译的时候,编译器对代码进行了优化和变换
汇编语言
汇编语言由助记符和对应的机器语言指令组成,汇编语言的源文件为 .asm
- 汇编语言与本地代码的关系 :用汇编语言编写的源代码中的每一条指令都对应着本地代码中的一条指令
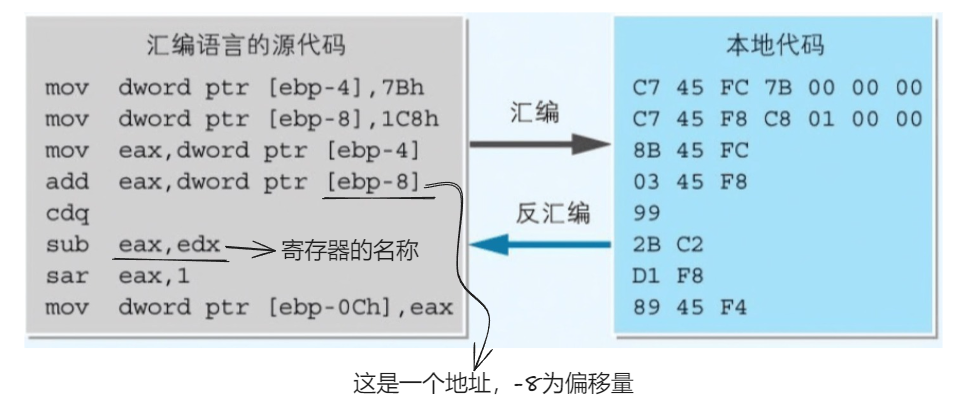
- 汇编语言中的指令:汇编语言指令的语法结构是操作码 + 操作数
- 汇编语言指令怎么写

计算机中的数据
什么是数字 IC?
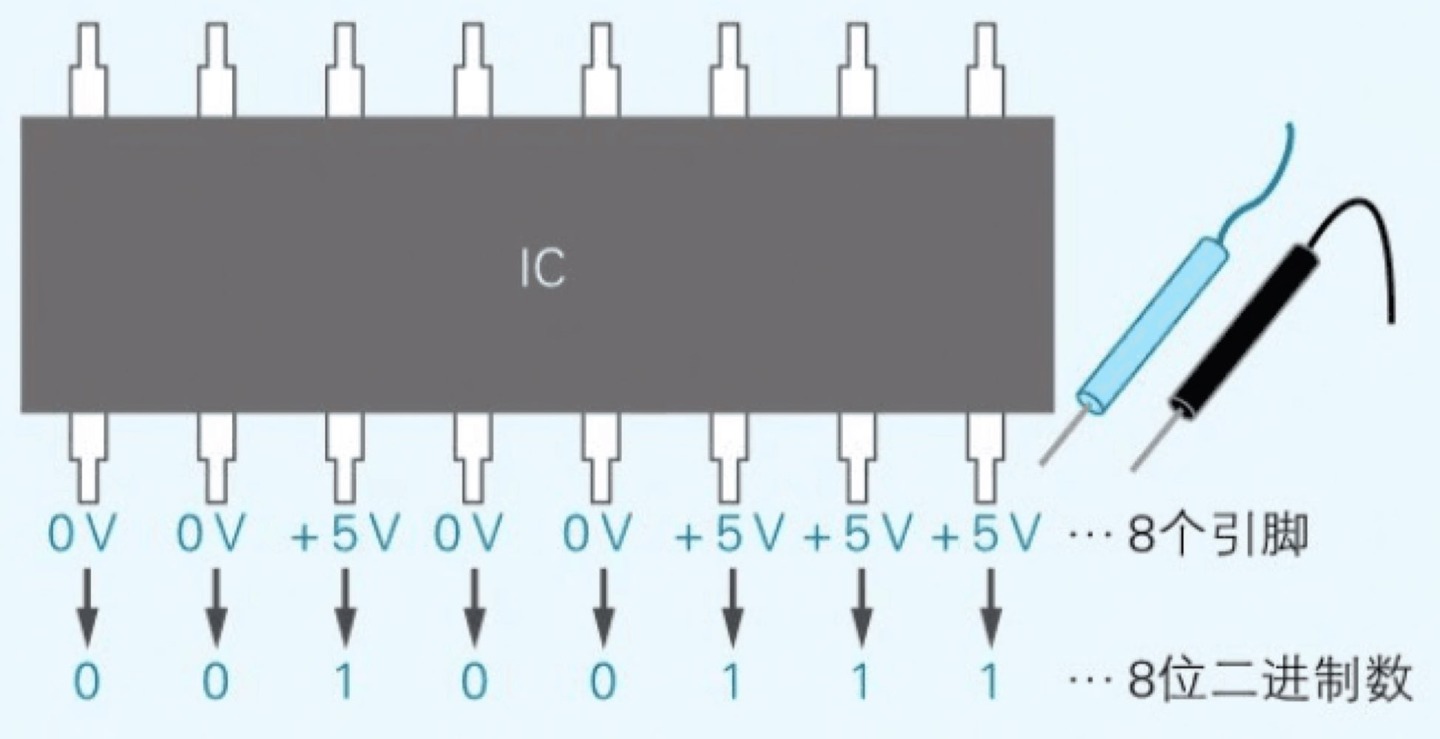
计算机中二进制位数的特点
二进制数的位数一般是 8 的倍数(8,16,32),因为计算机处理信息的基本单位是 1Byte(8bit)
整数运算
什么是补码 :补码就是用正数来表示负数
- 例如,用 8 位二进制数表示 - 1 时,只需求得 1(00000001)的补码即可。将 00000001 的各位数的 0 取反成 1,1 取反成 0,然后再将取反结果 + 1,最后就转换成了 - 1(11111111)
- 再例如,表示 - 5,5 的二进制数为 0101,吧 0101 取反 + 1,转换成了 1011(-5)
那为什么要用补码来表示负数呢 :因为所有的十进制计算在计算机里都是二进制的运算,所有的减法在计算机里都是加法。如果不用补码,那么 1-1 会等于 - 2
比如
0001-------------(1)
1001-------------(-1)
0001+1001=
1010-------------(-2)
0001-------------(1)
1111-------------(-1)
0001+1111=
10000------0000-------(0)补码为什么叫补码 :可能是因为一个数和它的补码相加为 0。其实你想想就知道,表示 -5 的时候是用 5 来表示的,那 - 5 与 5 本来就互为相反数。
- 其实你真的不用管什么老师教你的概念:正数的原反补都相同,负数的原反补要计算,还有什么,计算机里存的都是补码,不是原码
- 其实计算机里存的就是这样一些数字,只不过是用补码来表示负数而已
- 用 4 位二进制数表示,1000 表示的是 -8,而不是 0。因为 1000 所有位取反 +1 是 1000,1000 是 8,那么反过来原来的就是 -8
- 由于一个数和它的补码互为相反数,所以补码 ---> 取反 + 1---> 转换之前的数,-5(1011)------ 取反 + 1-------5(0101)
移位运算
移位运算能干嘛 :移位运算能代替乘法运算和除法运算
例如,将00100111左移两位的结果是10011100,左移两位后数值变成了原来的4倍。用十进制数表示的话,39(00100111)变成了156(10011100),也正好是4倍(39×4=156)移位操作时的补位 :
- 左移操作 :直接溢出丢弃,在低位处补 0
- 右移操作
- 逻辑右移 :高位补 0
- 算术右移 :负数高位补 1,正数高位补 0
小数运算
计算机可以精确地转换任何数字吗 :计算机是功能有限的机器设备,是无法计算无限循环小数的
- 实际上,十进制数 0.1 转换成二进制后,会变成 0.00011001100……(1100 循环)。这和无法用十进制数来表示 1/3 是一样的道理
如何解决小数的运算出错 :
- 回避策略 :由于误差很小,所以可以无视
- 把小数转换成整数进行运算
- 采用 BCD 方法
浮点数怎样表示 :IEE754
- (-1)^S * M * 2^E
- (-1)^S : 代表符号位。S 为 0 表示正数,S 为 1 表示负数 M : 类似科学计数法的有效数字。M 大于等于 1,小于 2 2^E : 指数位
十进制:5.5
二进制:101.1 ------->(-1)^0 * 1.011 * 2^2浮点数的空间划分 :
- Float :

- Double :1+11+52
浮点数的具体存储 :
- 有效数字 M :它一定是 1.几 这样的数,既然小数点前面总是 1,那我们就直接不存了,省下 1 bit 。等到最后要读取时,再把这个 1 加上
- E :E 是一个无符号数(unsigned int),所以 E 的取值范围是 0-255(8 bit)。但是在计数的时候 E 有可能出现负数(1.0 * 2^(-1)),所以规定在存入 E 的时候要加上中间数 127(Float)或 1023(Double)再存入
(-1)^0 * 1.011 * 2^2
S :0
M :011
E :129
实际存储:0 10000001 01100000000000000000000CPU
CPU 内部由寄存器,控制器,运算器,时钟四个部分构成,CPU 能够直接识别和执行的只有机器语言。使用 C,Java 等语言编写的程序,最后都会转化成机器语言。对程序员来说,CPU 是具有各种功能的寄存器的集合体
- CPU 的四大部分是怎么协同工作的 :程序启动后,根据时钟信号,控制器会从内存中读取指令和数据。通过对这些指令加以解释和运行,运算器就会对数据进行运算,控制器根据该运算结果来控制计算机
寄存器
寄存器可用来暂存指令,数据(用于运算的数值,表示内存地址的数值) ……,可以将其看作是内存的一种,但也有运算功能
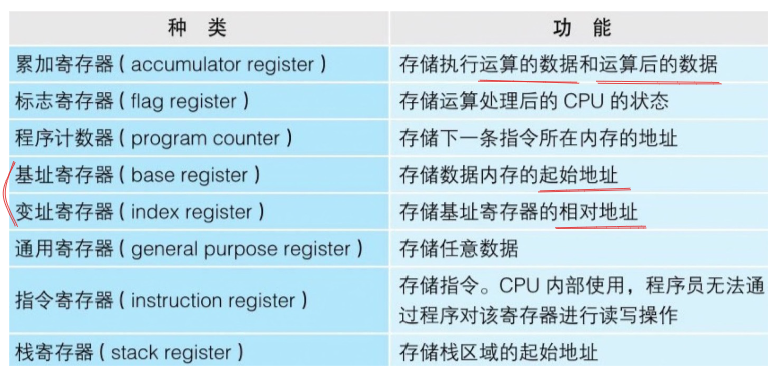 程序计数器,累加寄存器,标志寄存器,指令寄存器,栈寄存器都只有一个,其他的寄存器一般有多个
程序计数器,累加寄存器,标志寄存器,指令寄存器,栈寄存器都只有一个,其他的寄存器一般有多个
程序计数器
- 顺序执行时,是如何工作的
- 实际上,一个命令和数据通常被存储在多个地址上,但为了便于说明,把指令,数据分配到了一个地址
- Windows 等操作系统把程序从硬盘复制到内存后,会将程序计数器设定为 0100,然后程序便开始运行。CPU 每执行一个指令,程序计数器的值就会自动 +1。然后,CPU 的控制器就会参照程序计数器的数值,从内存中读取命令并执行。
- 程序计数器决定着程序的流程
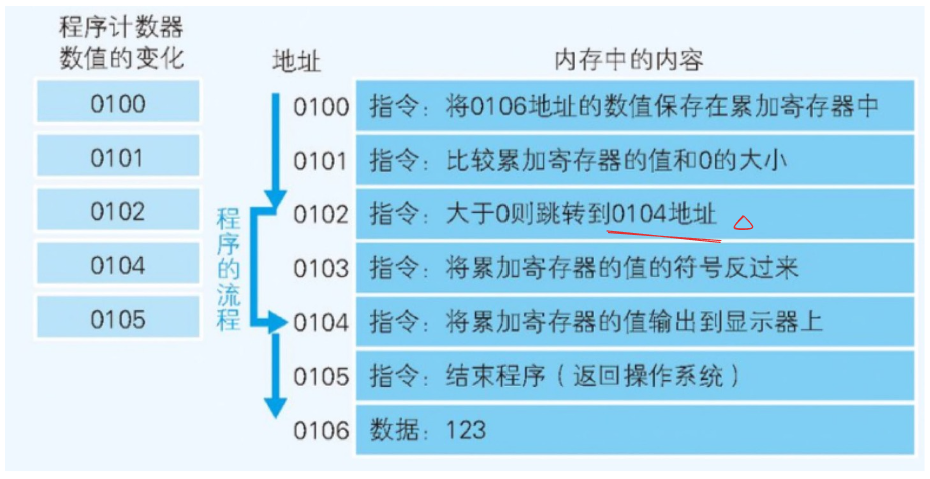
- 分支执行时,是如何工作的
标志寄存器
- 标志寄存器里面存储 CPU 的一些状态信息、存放溢出、奇偶校验
- 标志寄存器的数值会根据运算结果自动设定,后 3 个位用来存储比较运算的结果
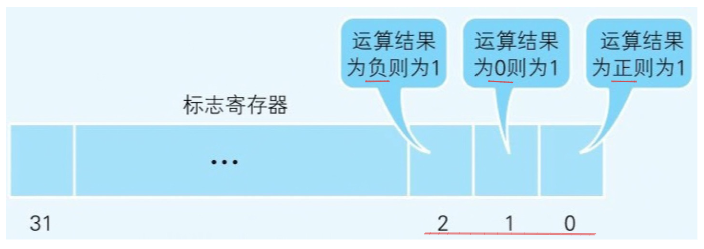
- 什么情况下会用到标志寄存器?
- 条件分支结构里的条件判断通常涉及到标志寄存器中的一些标志位
- 循环结构中,在每次循环时,CPU 都会检查标志寄存器的值,以确定是否需要继续执行循环代码段
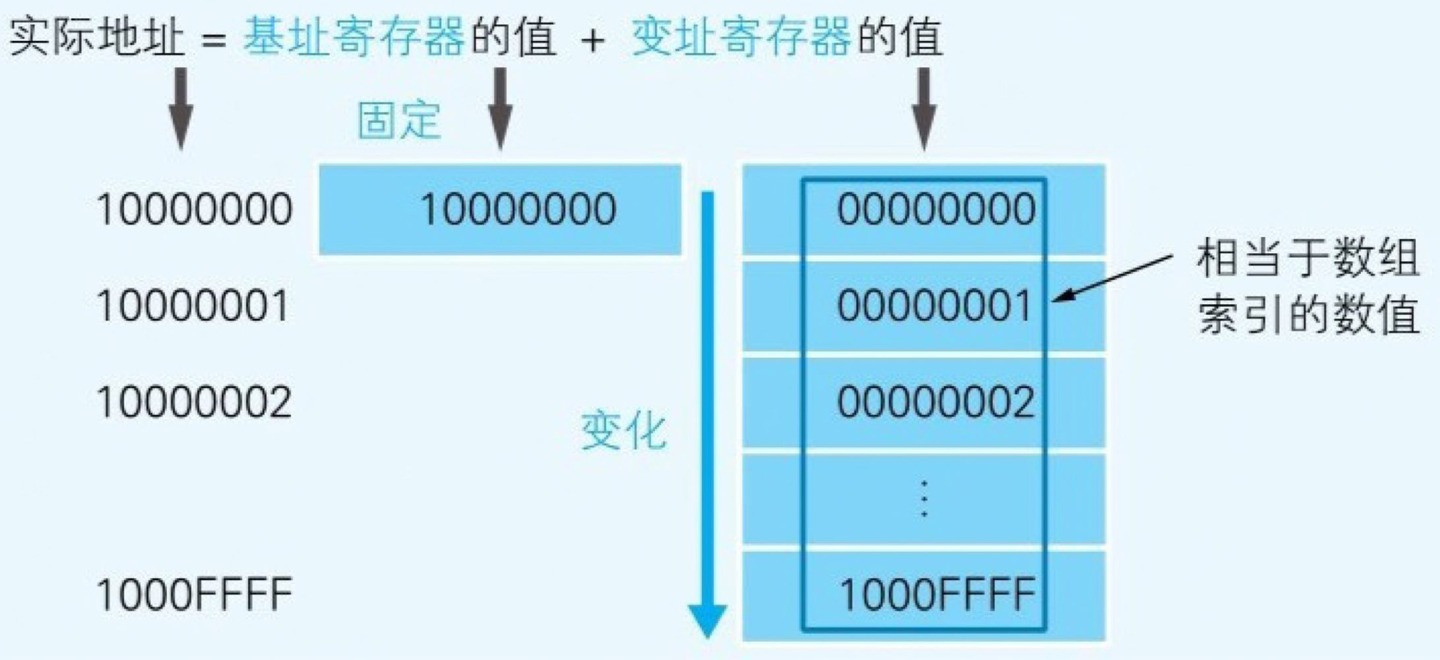
基址寄存器,变址寄存器
- 为什么 CPU 会有两个关于地址的寄存器 :我们用十六进制数将计算机内存上 00000000-FFFFFFFF 的地址划分出来,想查看某个范围的内存区域,只要有一个 32 位的寄存器,即可查看全部的内存地址
- 但如果想要像数组那样分割特定的内存区域以达到连续查看的目的,使用两个寄存器会更方便些,例如查看 10000000 地址 -1000FFFF 地址时,可以将 10000000 存入基址寄存器,并使变址寄存器的值在 00000000-0000FFFF 变化。CPU 则会把基址寄存器 + 变址寄存器的值解释为实际查看的内存地址。变址寄存器的值就相当于高级编程语言程序中数组的索引功能
累加寄存器
存储运算的结果、加减乘除、位运算的结果
控制器
[!quote] 控制器 控制器 负责把内存上的指令,数据等读入寄存器,并根据指令的执行结果来控制【
数据运算以外的处理,比如数据输入输出的时机控制,内存和磁盘等媒介的输入输出,键盘和鼠标的输入,显示器和打印机的输出】整个计算机
运算器
[!quote] 运算器 运算器 负责运算从内存读入寄存器的数据
时钟
[!quote] 时钟 时钟 负责发出 CPU 开始计时的时钟信号,有些计算机的时钟位于 CPU 的外部
内存
CPU 和内存的关系
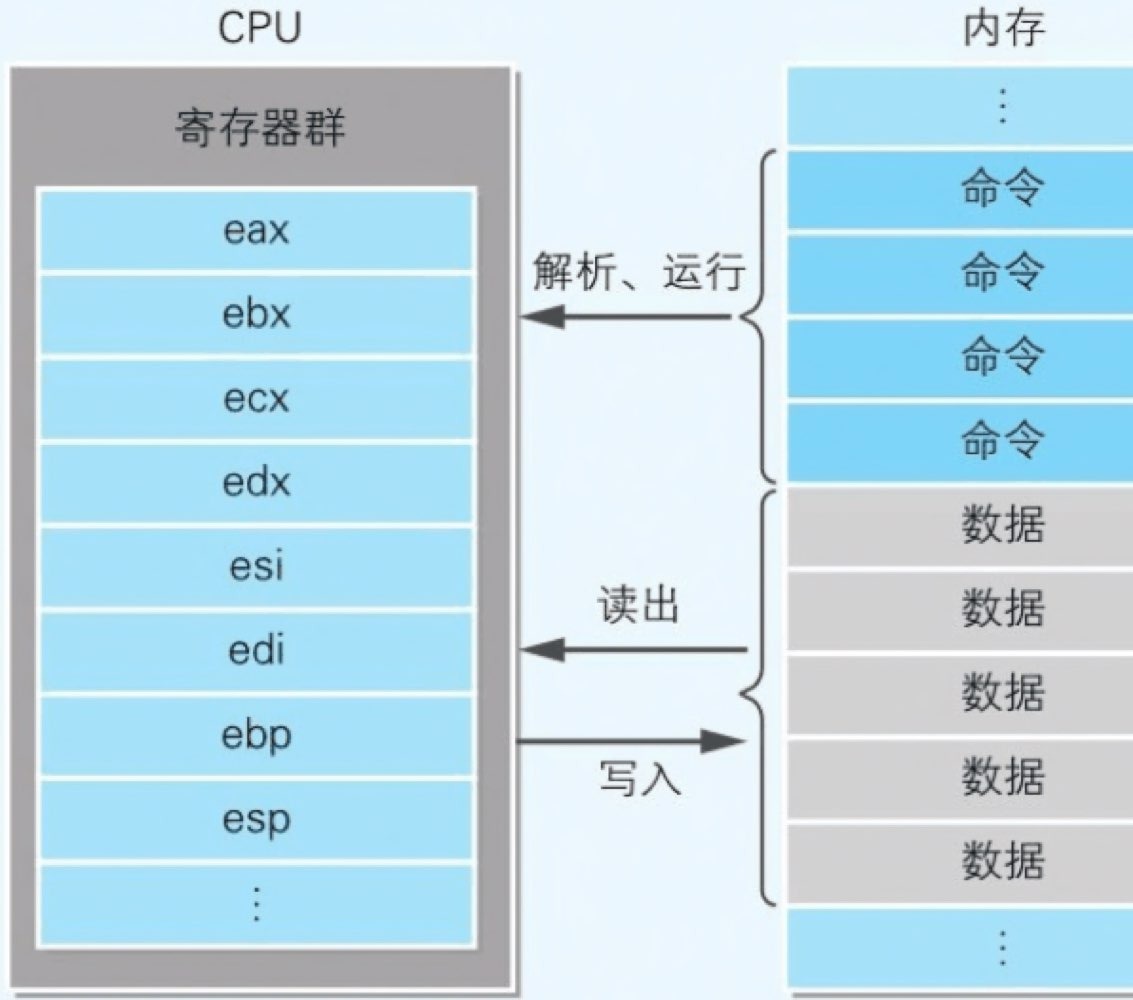
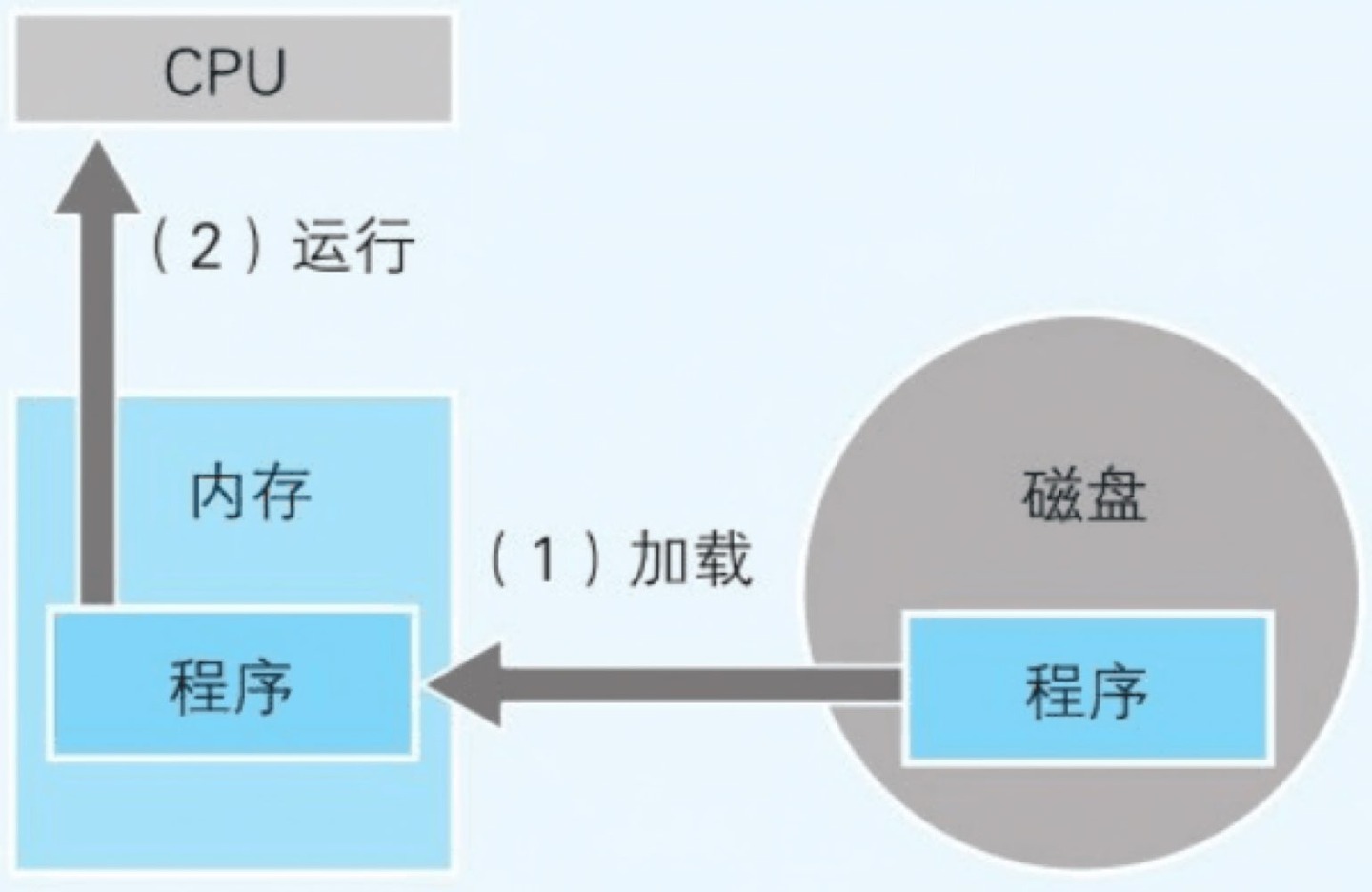
- 本地代码加载到内存后才能运行。内存中存储着构成本地代码的指令和数据
- 程序运行时,CPU 会从内存中把指令和数据读出,然后再将其存储在 CPU 内部的寄存器中进行处理
[!quote] 主存 主存 就是通常所说的内存【
也就是计算机的主存储器】
- 主要负责存储指令和数据。主存由可读写的元素构成,每个字节都带有一个地址编号【
CPU 可以通过该地址读取主存中的指令和数据,当然也可以写入数据】
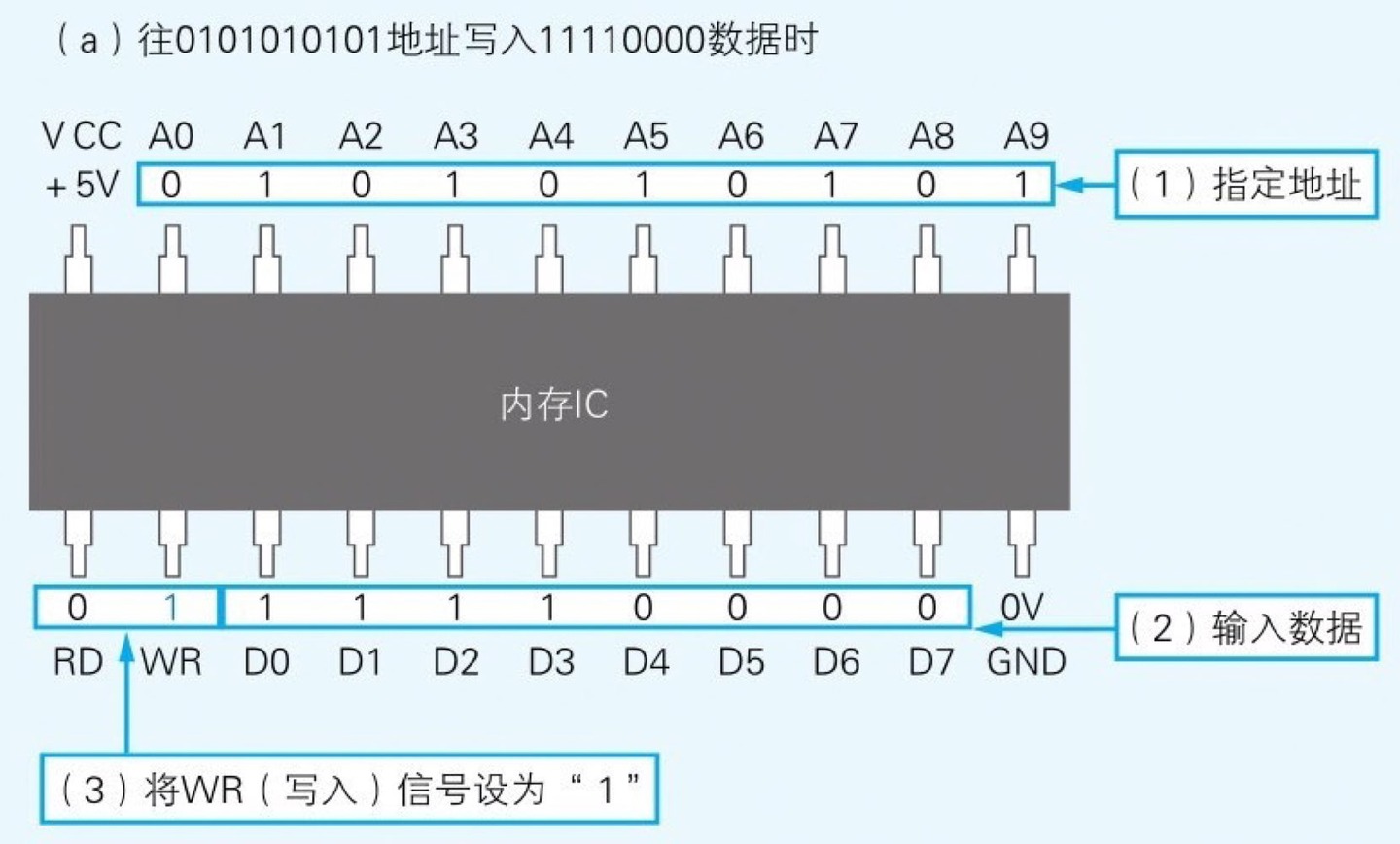
解读内存 IC
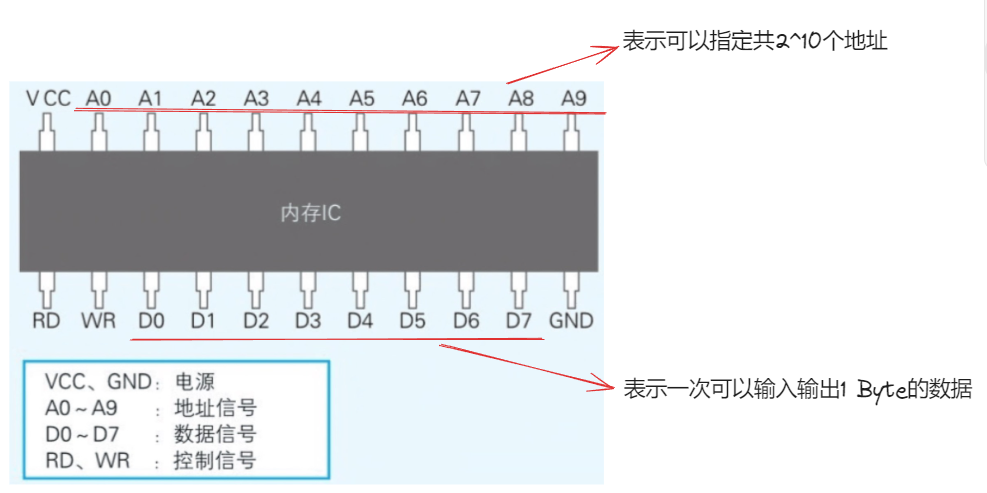 因此我们可以得出这个内存 IC 中可以存储 1024 个 1 字节的数据
因此我们可以得出这个内存 IC 中可以存储 1024 个 1 字节的数据
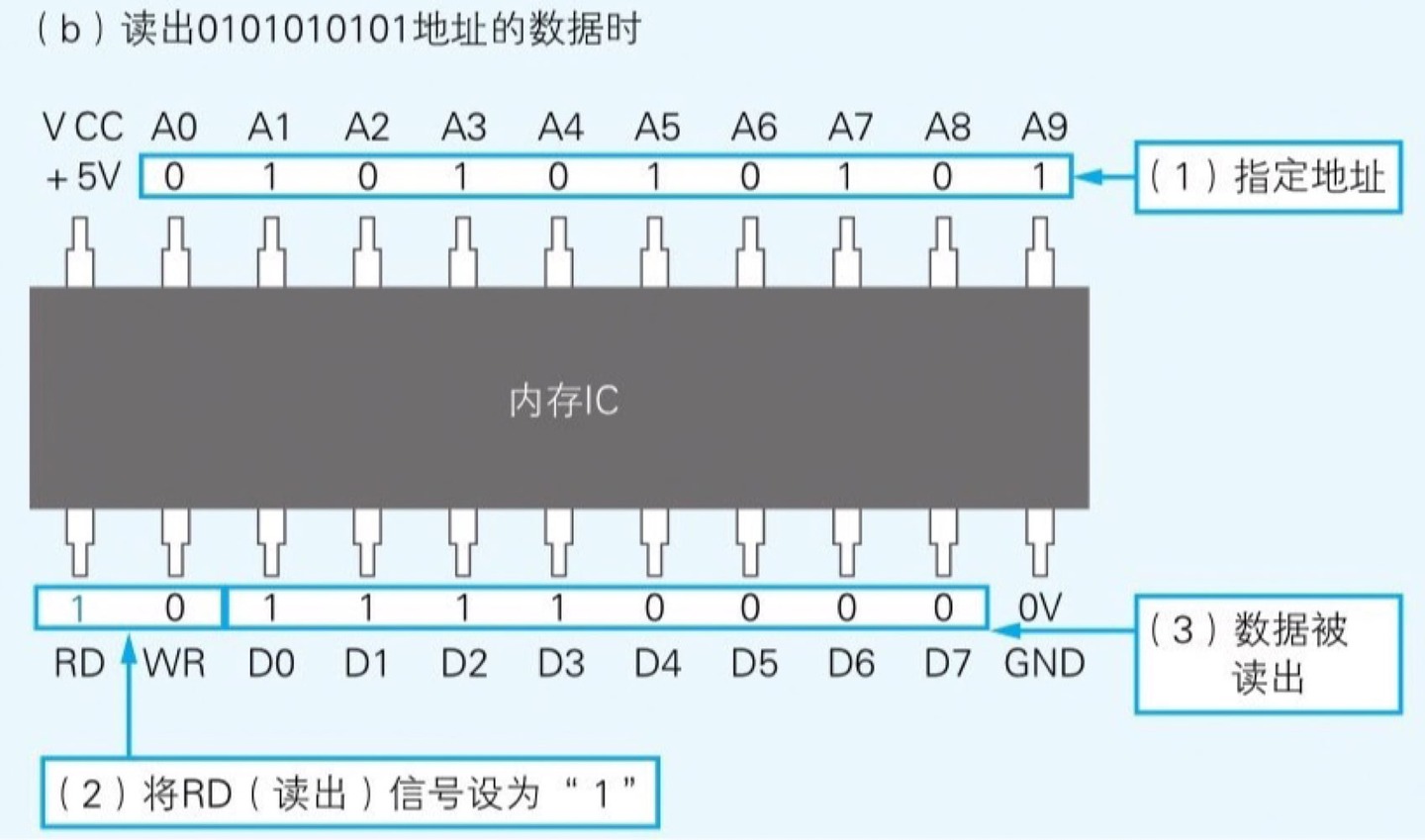
显地址,隐地址

显示内存地址:在一些低级语言或汇编语言中,程序员需要显式地指定内存地址(例如指针操作,内存分配,释放等)
- 程序员可以直接控制内存地址的分配和管理
隐式内存地址:在高级语言中,程序员是使用变量和数据结构等抽象概念来描述内存中的数据
- 由编译器和操作系统自动完成内存地址的分配
[!quote] 内存映射 内存映射 就是操作系统负责将进程中的虚拟地址映射到物理内存地址上
- 当程序需要访问某个变量或数据结构时,会进行内存映射,然后将数据从内存中读取到处理器中进行操作
为什么要有栈和队列?
如果只有数组,每次保存临时数据都需要指定地址和索引,程序就会变得很麻烦。如果我们用栈和队列提前确定好了写入和读出的顺序,就不用在指定地址和索引了
指针
指针的内存大小
指针也是一种变量,它所表示的不是数据的值,而是存储着数据的内存的地址。在 windows 上使用的程序通常都是 32 位(4 字节)的内存地址。这种情况下,指针变量的长度也是 32 位,所以它的内存大小是 4 个字节 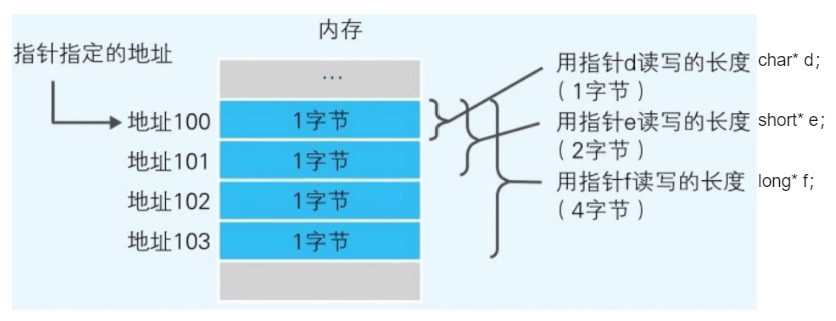
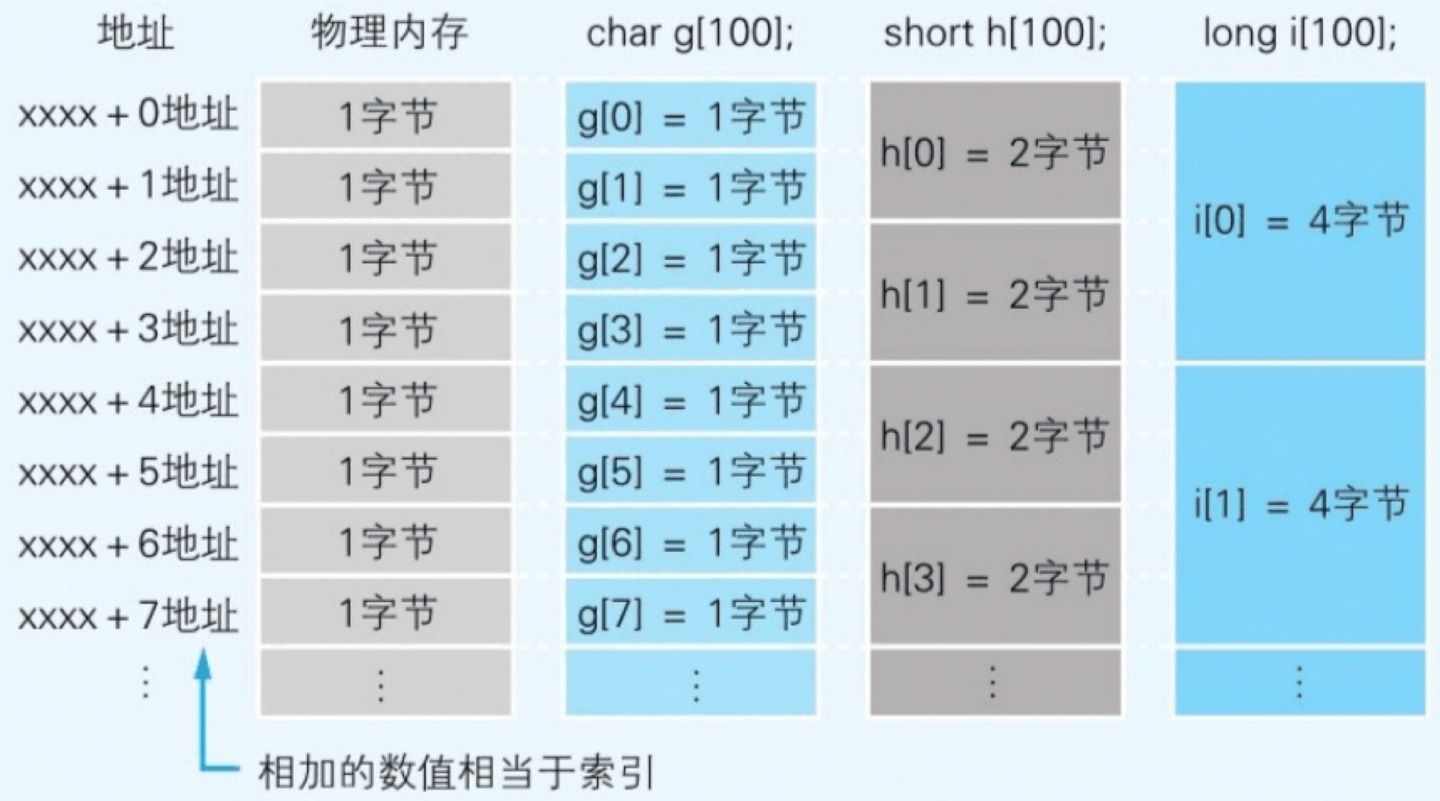
磁盘
- 扇区是磁盘保存数据的物理单位
- 磁盘中存储的程序,必须加载到内存后才能运行
硬盘
硬盘通常安装在计算机的机箱内部,更加可靠,因为它们使用的存储介质较为坚固,不容易出现损坏或数据丢失的情况
软盘
软盘通常使用在旧式计算机或一些便携式设备上,存储容量通常较小,读写速度也慢得多,可靠性也比较低
磁盘缓存机制
把从磁盘中读出的数据存储到内存空间中 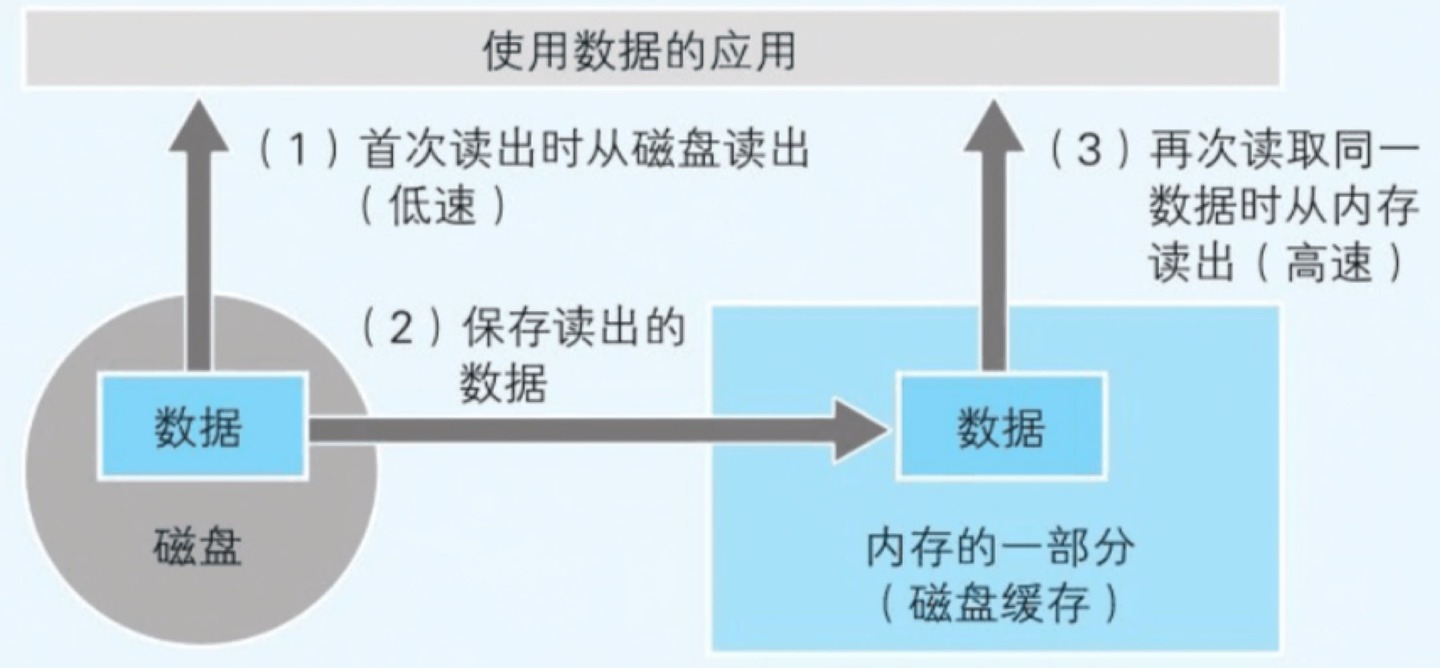 当接下来需要读取同一数据时,就不用通过实际的磁盘,而是从磁盘缓存中把内容读出
当接下来需要读取同一数据时,就不用通过实际的磁盘,而是从磁盘缓存中把内容读出
虚拟内存
把磁盘的一部分作为假想的内存来使用
虚拟内存地址使得系统可以在有限的物理内存下运行更多的程序。当系统中运行的程序需要的内存超出了物理内存的限制时,操作系统会将一部分程序数据暂时保存到硬盘上的虚拟内存中,以便给其他程序腾出更多的物理内存。这样就可以让更多的程序同时运行,提高了系统的内存利用率
虚拟内存地址可以提高系统的安全性。由于每个程序都被分配了独立的虚拟内存地址空间,因此一个程序无法直接访问另一个程序的内存空间。防止了程序之间的干扰和恶意攻击
- 分页式虚拟内存
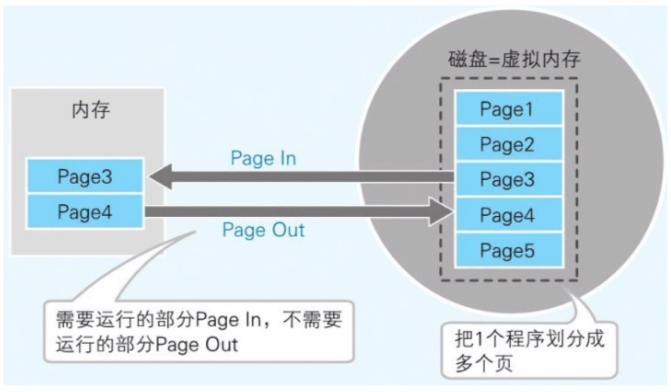
在不考虑程序构造的情况下,把运行的程序按照一定大小的页进行分割,并以页为单位在内存和磁盘间进行置换。(一般情况下,windows 计算机的页的大小是 4KB )
节约内存的编程方法
通过 DLL 文件实现函数共有
假设我们编写了一个具有某些功能的函数 MyFunc()。应用 A 和应用 B 都会使用这个函数。在两个应用上的运行文件中内置函数 MyFunc()(这个称为 Static Link 静态链接)后同时运行这两个应用,内存中就存在了具有同一函数的两个程序。这就会内存的利用效率降低

同一个 DLL 文件的内容在运行时可以被多个应用共有,因此内存中存在的函数 MyFunc() 的程序就只有一个
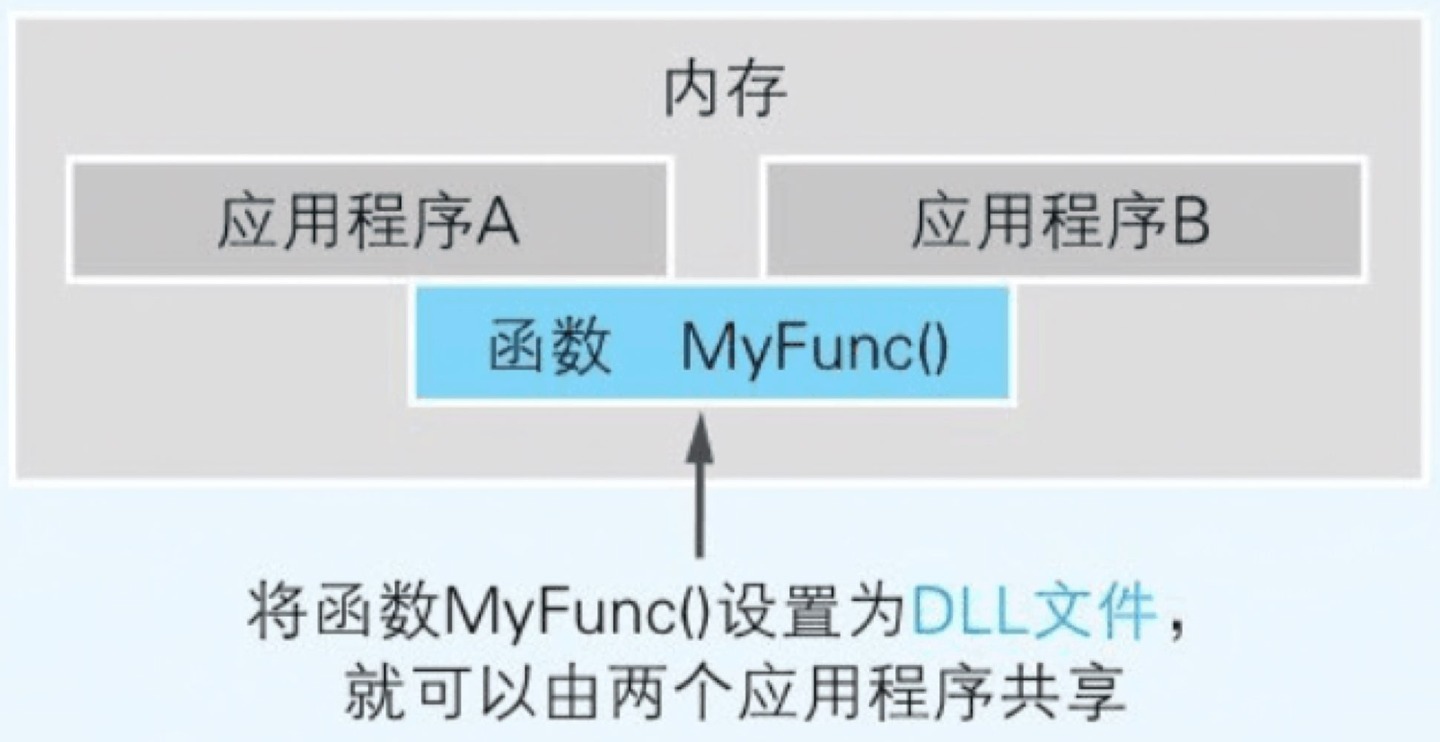
通过调用 stdcall
window 提供的 DLL 文件内的函数,基本上都是 stdcall 调用方式 
物理结构
扇区方式
固定长度的空间
一般 windows 使用的,windows 中使用的磁盘,一般 1 个扇区 是 512 字节
- 什么是扇区 :扇区是对磁盘进行物理读写的最小单位
- 什么是簇 :簇是文件系统中的基本存储单位
在逻辑方面(软件方面)对磁盘进行读写上的单位是扇区整数倍簇
- 簇的容量和数量的权衡 :不管是多么小的文件,都会占用 1 簇的空间

所以文件系统需要在簇的容量和数量之间进行权衡
可变长方式
长度可变的空间
文件
$$ 文件 是字节数据的集合体 $$
文件与文件系统
- 文件存储的基本单位是 1 字节
- 文件系统存储的基本单位是簇
压缩
压缩机制
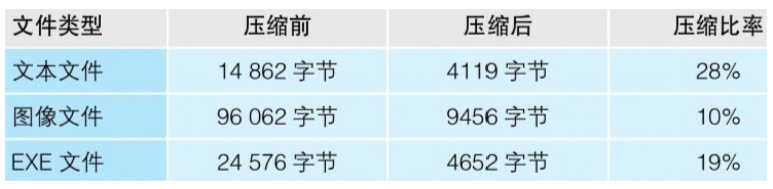
RLE 算法 :把文件内容用 “数据 × 重复次数” 的形式来表示 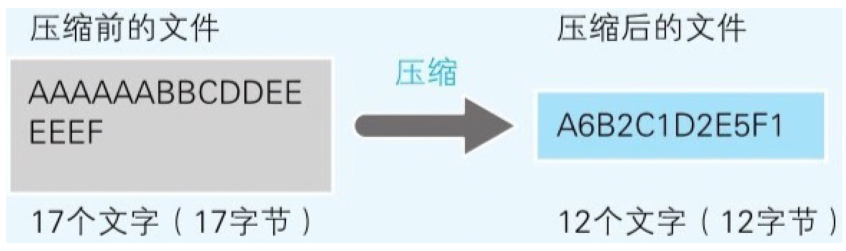 经常被用于压缩传真的图像,但它并不适合文本文件的压缩
经常被用于压缩传真的图像,但它并不适合文本文件的压缩 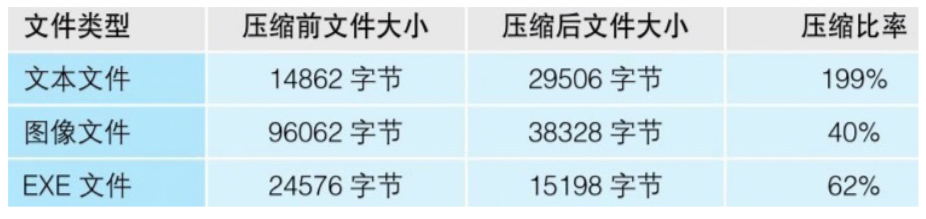
哈夫曼算法 :多次出现的数据用小于 8 位的字节数来表示,不常用的数据则可以用超过 8 位的字节数来表示 
- 不同文件的哈夫曼编码信息是不同的,因为有可能 A 文件字符 m 的出现频率很高,这时我们给 m 的编码长度就最短。但是 B 文件字符 m 出现的频率很低,那这时对应的哈夫曼编码又不同了
例如,在某一个文本文件中,A出现了100次,Q出现了3次
--默认时,A和Q都用8位(1字节)来表示时,源文件的大小就是100次×8位 + 3次×8位 = 824位
--假设使用哈夫曼算法,A用2位,Q用10位来表示,压缩后的大小就是100次×2位 + 3次×10位 = 230位再例如,压缩 AAAAAABBCDDEEEEEF 这时候会出现一个问题,100 这个 3 位的编码,它的意思是用 1,0,0 这 3 个编码来表示 E,A,A 呢?还是用 10,0 这两个编码来表示 B,A 呢?亦或是用 100 来表示 C 呢? 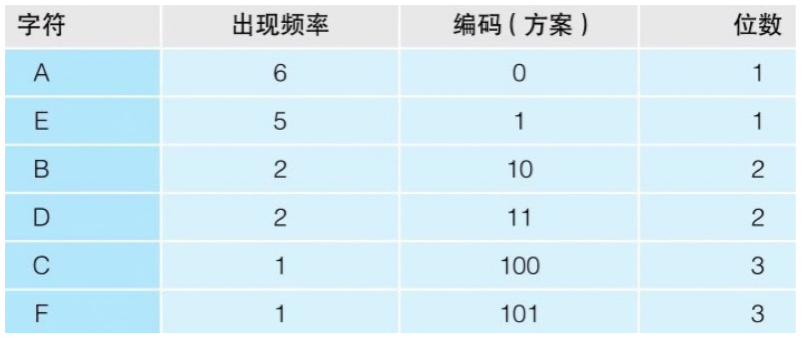 解决办法:
解决办法:
- 加入用来区分字符的符号
- 借助哈夫曼树构造编码体系

压缩方式
- 可逆压缩
- 非可逆压缩

图像的压缩
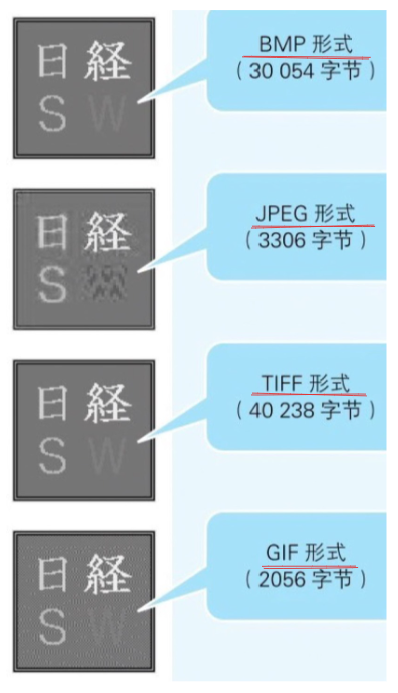
- BMP :Windows 的标准图像数据形式
- JPEG :1、把构成图像的点阵的颜色信息由 RGB 形式转化成 YCbCr(亮度,蓝色色度,红色 色度)形式。人眼对亮度很敏感,但对颜色的变化却有些迟钝。因此,亮度 Y 就是一个很重要的 参数,而表示颜色的 Cb,Cr 则没有那么重要。于是我们通过减少 Cb 和 Cr 的信息间距来缩小图像 数据的大小,然后再哈夫曼编码。 2、将每个点的色素变化看作是波形的信号变化,进行傅里叶变换。照片等图像文件的特点 是低频率(柔和的颜色变化)的部分较多,高频率(强烈的颜色变化)的部分较少。因此,我 们把高频率的部分剪切掉(人眼分辨不出来什么差别)。这样一来,图像数据也就会缩小。再 哈夫曼编码。
- TIFF :通过在文件头中包含”标签“就能够显示出数据性质的图像数据形式
- GIF :要求色数不超过 256 色
可执行文件(.exe)
Dump :把文件的内容,每个字节用 2 位十六进制数来表示的方式 
当一个程序被编译和链接为可执行文件(.EXE 文件)后,其中的变量和函数都被分配了虚拟内存地址
为了实现虚拟内存地址到物理内存地址的转换,链接器会在.EXE 文件的开头添加一些必要的信息,这些信息被称为再配置信息(relocation information)
每当程序被加载到内存中时,操作系统会根据再配置信息来对程序进行地址转换,将程序中的虚拟内存地址映射到实际的物理内存地址上。这样,程序就可以正常地访问变量和函数了
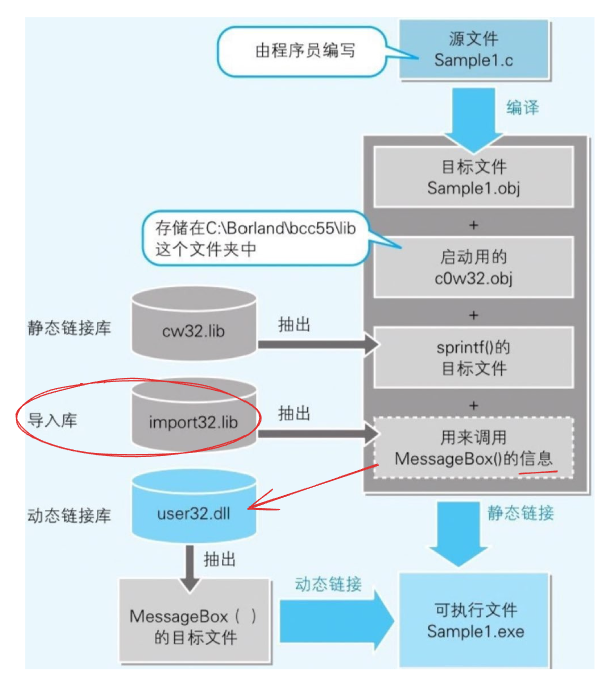
库文件
库文件 可以增加链接器在链接时的效率
静态链接库(.lib) :静态链接库是包含可重用代码和数据的文件
- 静态链接库在编译时被链接到程序中,链接后的可执行文件中包含了静态链接库中的代码和数据(这意味着,当程序运行时,所需的函数和代码已经被完全复制到可执行文件中,程序不需要再依赖于外部的库文件)
- 静态链接库的优点是方便移植和分发,但是每个可执行文件的大小可能会很大
动态链接库(.dll) :动态链接库是一种特殊的库文件,它是在程序运行时动态加载到内存中的
- 动态链接库在程序运行时被加载到内存中,程序通过调用动态链接库中的函数来使用其功能(这意味着,当程序运行时,它需要依赖于外部的库文件)
- 动态链接库的优点是可以在多个应用程序之间共享代码和数据,动态链接库的更新也相对容易 但是会增加程序启动时间和运行时的开销
Windows 中,API 的目标文件,就是存储在 DLL 中
导入库 :导入库是在编译可执行文件时使用的特殊库文件,其中包含了程序需要使用的一个或多个 dll 文件中的函数的名称和入口点地址
- 导入库的作用是告诉编译器程序需要使用哪些动态链接库的函数,以便在程序运行时能够正确地链接到这些函数
运行环境
运行环境 = 操作系统 + 硬件
在 MS-DOS 上,不同机型的应用是不同的;在 Windows 上,则可以使用同一个应用 在 MS-DOS 上,应用大多都是不经过操作系统而直接控制硬件的;在 Windows 上,应用则基本上由 Windows 来完成对硬件的控制 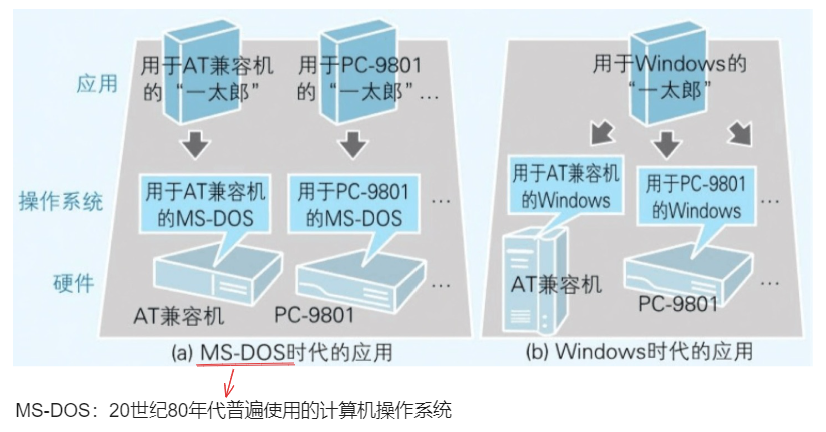
应用程序必须根据不同的操作系统类型来专门开发。因为操作系统的类型不同,API(应用程序向操作系统传递指令的途径)也是不同的;同样的道理,CPU 的类型不同,所对应的机器语言也不同 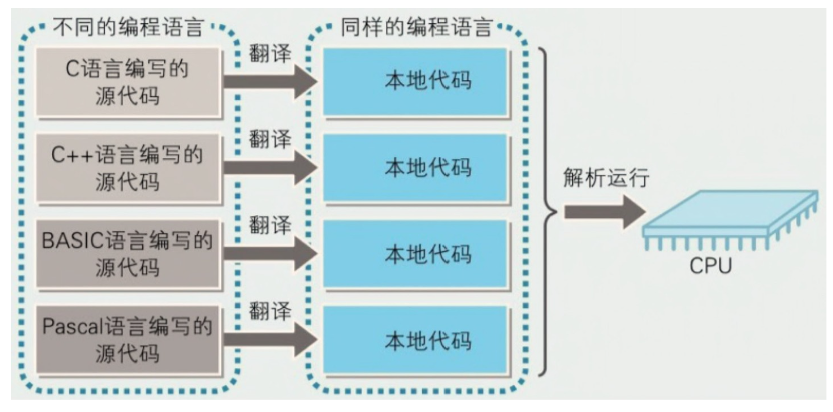
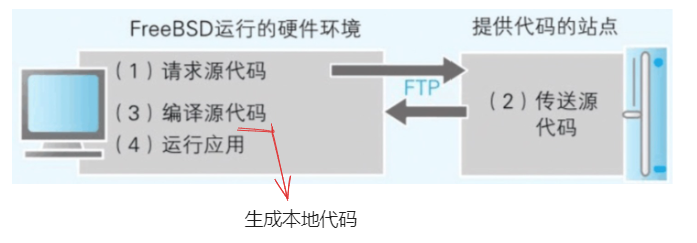
能克服 CPU 在内的所有硬件差异的系统 :
- FreeBSD
- Java 虚拟机
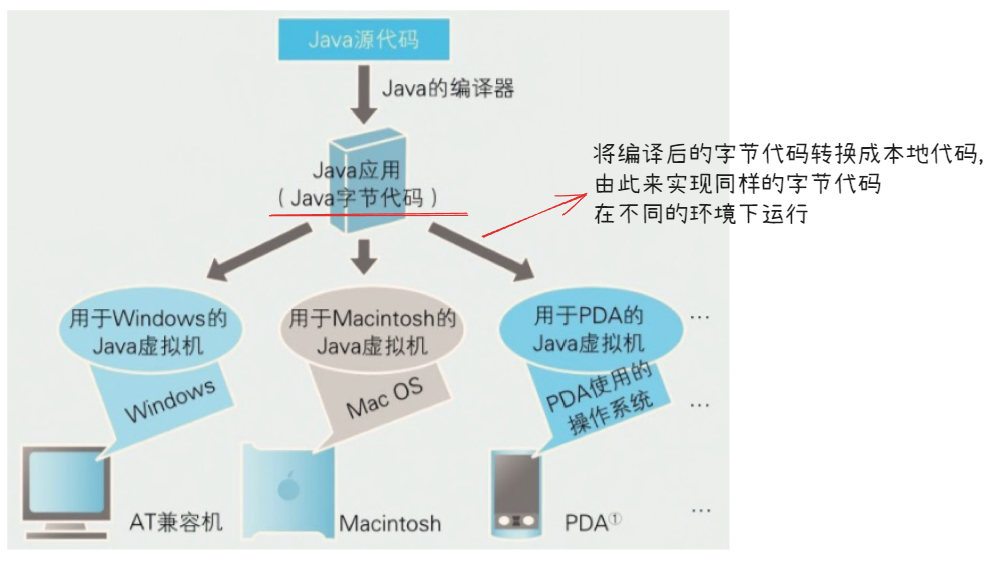
Java 虚拟机是一边把 Java 字节代码逐一转换成本地代码一边运行的,缺点 :
- 想让所有字节代码在任意 Java 虚拟机上运行是比较困难的
- 当我们使用只适用于某些特定硬件的功能时,就会出现在其他 Java 虚拟机行,或者功能使用受限等情况
- Java 虚拟机每次运行时都要把字节代码变换为本机代码,这就导致了运行速度慢
输入、输出设备
应用与 IN,OUT 硬件之间的关系
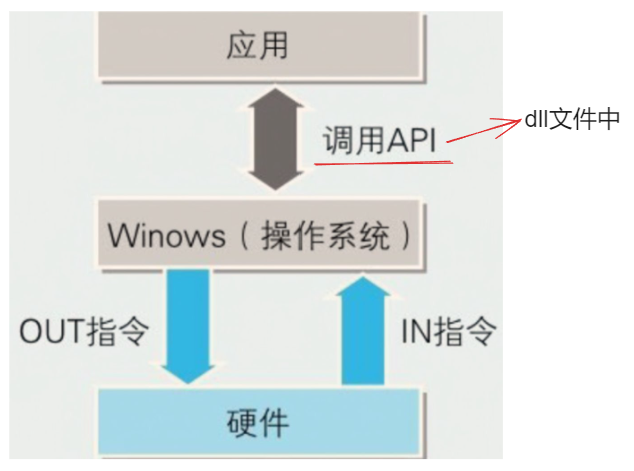
假设要在窗口中显示字符串,就可以使用 Windows API 中的 TextOut 函数
识别外围设备的三大组合
I/O 端口号
IRQ
DMA 通道
后两者不是所有外围设备都具备,因为有些外围设备不需要
IO 控制器
交换计算机主机和外围设备之间电流特性的 IC 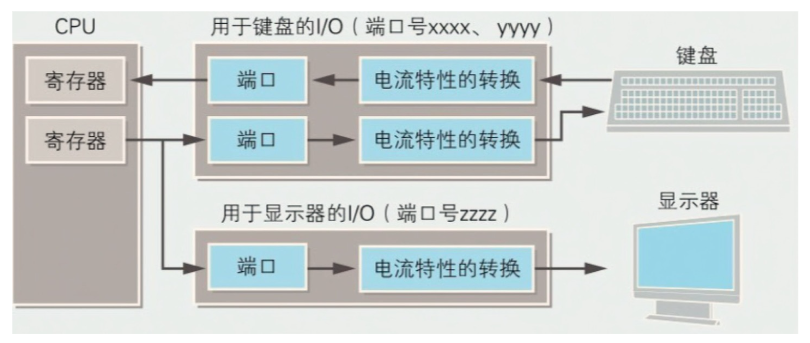 除了显卡,网卡等特殊 IO,其他 IO 都是在主板上的显示器,键盘等外围设备都有各自专用的 IO 控制器
除了显卡,网卡等特殊 IO,其他 IO 都是在主板上的显示器,键盘等外围设备都有各自专用的 IO 控制器
IO 控制器中也有寄存器,它无法运算处理数据,只能存储数据, 一个 IO 控制器有多个端口(一个端口有一个端口号),可以控制多个外围设备,但是每个端口都有一个特定的用途
IRQ
IRQ Interrupt Request
- 请求中断处理程序:IO 控制器实施中断处理程序:CPU
- 当有多个外围设备同时发送中断请求时,CPU 也会为难,所以在 IO 控制器和 CPU 之间加入了中断控制器
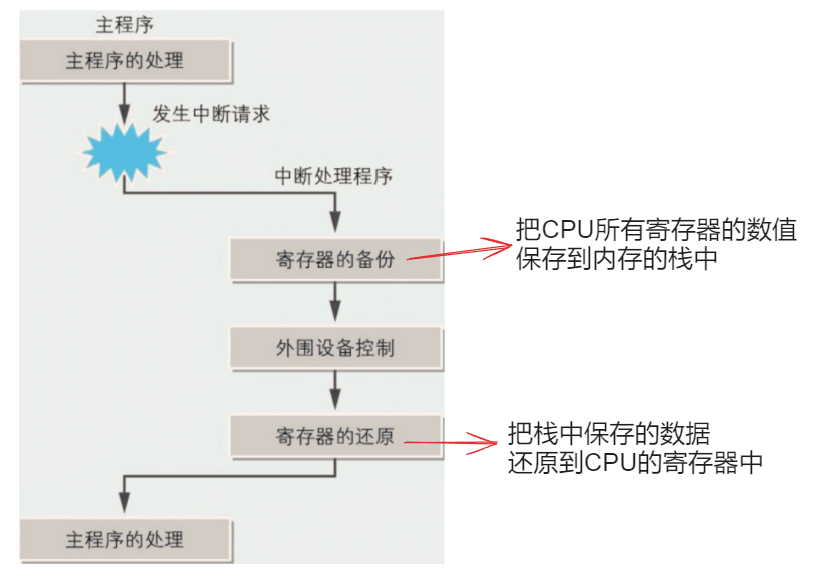
中断请求处理有什么用 :
- 比如主程序正在调查是否有鼠标输入,就在这时发生了键盘输入,如果没有中断处理请求,那就会导致键盘输入的内容无法实时显示。
- 在没有中断处理请求时,计算机主机会不断地向打印机发送数据以进行打印。如果打印机出现问题(例如缺纸,卡纸),计算机主机不得不等待打印机解决问题并恢复正常工作,然后才能继续向打印机发送数据。这样会浪费大量的计算机主机处理时间,并且会导致整个系统变得非常缓慢。在有中断处理请求时,如果打印机出现问题,计算机主机会向打印机发送一个中断请求。然后计算机主机就可以在等待期间执行其他任务,在打印机解决问题并准备好接收数据时,它会向计算机主机发送一个中断响应,以便计算机主机可以继续向打印机发送数据。这个过程会不断重复,直到所有数据都已经被打印出来为止
DMA
direct memory access 在不通过 CPU 的情况下,外围设备直接和主内存进行数据传送 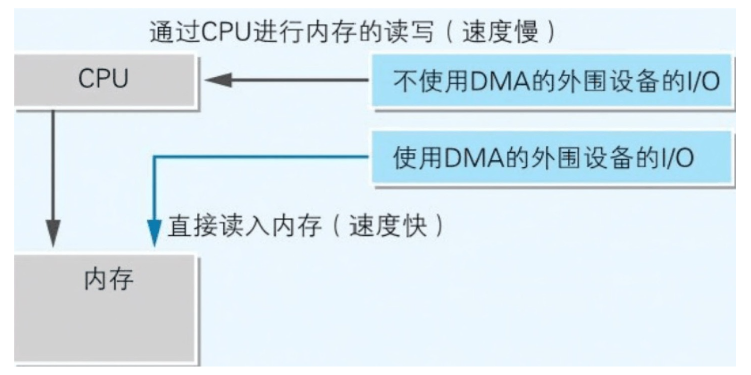
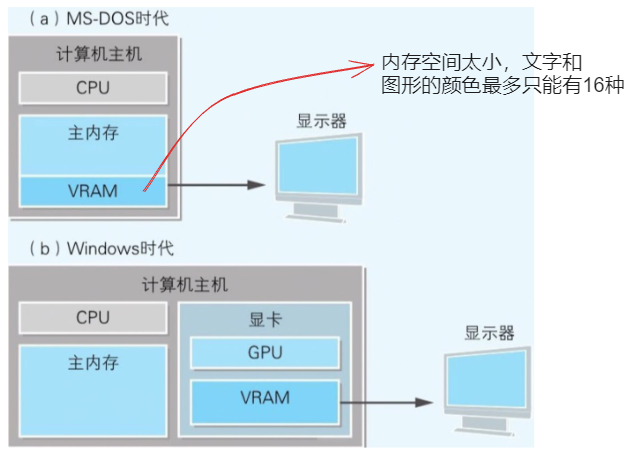
显示器
显示器中显示的信息一直存储在某内存中(VRAM),在程序中,只要往 VRAM 中写入数据,该数据就会在显示器中显示出来