2-2 数据结构命令
[!quote] Redis 支持的数据结构
- 基本数据类型
字符串 String【默认】:可存储 512 MB列表 List字符串有序列表,支持索引,按照插入顺序排序【可以头插,尾插】。可存储 40 多亿元素集合 Set字符串无序列表,集合中不允许有重复值,通过哈希表实现有序集合 ZSet字符串集合,且不允许重复的成员,每个元素都会关联一个 double 类型的分数【分数可以重复】,通过分数来为集合中的成员进行从小到大的排序哈希 Hash键值对集合,可存储 40 多亿个键值对,适合存储对象- 高级数据类型
- 消息队列 Stream
- 地理空间 Geospatial
- HyperLogLog
- 位图 Bitmap
- 位域 Bitfield
[!hint] 使用
type 键来查看 value 的数据类型
字符串
创建
SET 键 值设置键值对GETSET 键 值设置键值对,并返回旧 value【如果没有,则返回 nil】mset 键1 值 键2 值 ……一次性设置多个键值对msetnx 键1 值 键2 值 ……当 key 不存在时,一次性设置多个键值对
# mset
127.0.0.1:6379> mset name2 docker name3 mysql
OK
127.0.0.1:6379> get name2
docker
127.0.0.1:6379> get name3
mysql获取
GET 键GETRANGE 键 索引1 索引2获取 value 中的指定范围的字符MSET 键1 键2 ……一次性获取多个 value【如果 key 不存在,则返回 nil】Strlen 键获取 value 的字符长度
修改
SETRANGE 键 索引 值将 value 中,指定索引之后的值,进行替换append 键 值向 value 后面添加字符incr 键如果 value 为数字,则将 value 加 1incrby 键 值如果 value 为数字,则将 value 加上指定的值incrbyfloat 键 值如果 value 为数字,则将 value 加上指定的浮点数值decr 键如果 value 为数字,则将 value 减 1decrby 键……
redis 127.0.0.1:6379> SET key1 "Hello World"
OK
redis 127.0.0.1:6379> SETRANGE key1 6 "Redis"
(integer) 11
redis 127.0.0.1:6379> GET key1
"Hello Redis"删除
DEL 键
SET name redis
GET name
DEL name
---
"redis"列表 List
- 增
- 左插入
lpush 集合名 值 - 右插入
rpush 集合名 值
- 左插入
- 删
- 左删除几个元素
lpop 集合名 [数字]【不加数字表示删除一个】 - 右删除几个元素
rpop 集合名 [数字] - 只保留索引 1 到索引 2 之间的元素
LTRIM 集合名 索引1 索引2
- 左删除几个元素
- 查
- 查看列表元素个数
LLEN 集合名 - 按照索引遍历集合
lrange 集合名 索引1 索引2【索引 2 如果是 “-1”,表示最后一个元素】
- 查看列表元素个数
| 序号 | 命令及描述 |
|---|---|
| 1 | BLPOP key1 [key2 ] timeout 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 2 | BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 3 | BRPOPLPUSH source destination timeout 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 4 | LINDEX key index 通过索引获取列表中的元素 |
| 5 | [LINSERT key BEFORE |
| 6 | LLEN key 获取列表长度 |
| 7 | LPOP key 移出并获取列表的第一个元素 |
| 8 | LPUSH key value1 [value2] 将一个或多个值插入到列表头部 |
| 9 | LPUSHX key value 将一个值插入到已存在的列表头部 |
| 10 | LRANGE key start stop 获取列表指定范围内的元素 |
| 11 | LREM key count value 移除列表元素 |
| 12 | LSET key index value 通过索引设置列表元素的值 |
| 13 | LTRIM key start stop 对一个列表进行修剪 (trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。 |
| 14 | RPOP key 移除列表的最后一个元素,返回值为移除的元素。 |
| 15 | RPOPLPUSH source destination 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
| 16 | RPUSH key value1 [value2] 在列表中添加一个或多个值到列表尾部 |
| 17 | RPUSHX key value 为已存在的列表添加值 |
# 会返回列表的长度
127.0.0.1:6379> lpush list1 rerere
(integer) 1
127.0.0.1:6379> lpush list1 rere2
(integer) 2
127.0.0.1:6379> rpush list1 rere3
(integer) 3
127.0.0.1:6379> lrange list1 0 2
1) "rere2"
2) "rerere"
3) "rere3"
# 从0开始遍历,知道最后一个元素
127.0.0.1:6379> lrange list1 0 -1
1) "rere2"
2) "rerere"
3) "rere3"集合 Set
- 增
sadd 集合名 值 - 删
SREM 集合名 值 - 查
- 遍历
smembers 集合名 - 判断某个值是否在集合中
SISMEMBER 集合名 值
- 遍历
| 序号 | 命令及描述 |
|---|---|
| 1 | SADD key member1 [member2] |
| 2 | SCARD key |
| 3 | SDIFF key1 [key2] |
| 4 | SDIFFSTORE destination key1 [key2] |
| 5 | SINTER key1 [key2] |
| 6 | SINTERSTORE destination key1 [key2] |
| 7 | SISMEMBER key member |
| 8 | SMEMBERS key |
| 9 | SMOVE source destination member |
| 10 | SPOP key |
| 11 | SRANDMEMBER key [count] |
| 12 | SREM key member1 [member2] |
| 13 | SUNION key1 [key2] |
| 14 | SUNIONSTORE destination key1 [key2] |
| 15 |
127.0.0.1:6379> sadd set1 green
(integer) 1
127.0.0.1:6379> sadd set1 red
(integer) 1
# 返回0,表示集合中已经有了相同的值
127.0.0.1:6379> sadd set1 red
(integer) 0
127.0.0.1:6379> sadd set1 black
(integer) 1
127.0.0.1:6379> SMEMBERS set1
1) "green"
2) "red"
3) "black"
127.0.0.1:6379> SISMEMBER red
(integer) 1有序集合 ZSet
- 增
zadd 集合名 分数 值添加分数和值
- 查
- 获取某个值的分数
ZSCORE 集合名 值 - 获取某个值的排名
ZRANK 集合名 值 - 反向获取某个值的排名
ZREVRANK 集合名 值 - 遍历
- 根据分数范围遍历集合
ZRANGEBYSCORE 集合名 分数1 分数2 - 根据索引遍历值
ZRANGE 集合名 索引1 索引2 - 根据索引遍历值,和分数
ZRANGE 集合名 索引1 索引2 WITHSCORES
- 根据分数范围遍历集合
- 获取某个值的分数
redis 127.0.0.1:6379> zadd runoob 0 redis
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 mongodb
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabbitmq
(integer) 1
redis 127.0.0.1:6379> ZRANGEBYSCORE runoob 0 1000
1) "mongodb"
2) "rabbitmq"
3) "redis"哈希 Hash
- 增
hset 集合名 键 值HMSET 集合名 键名1 值1 键名2 值2 ……一次设置多个键值对
- 查
HGET 集合名 键名查看某个 valuehmget 集合名 键1 键2 ……hexists 集合名 键查看键是否存在hgetall 集合名查看所有的 key,和 valuehkeys 集合名查看哈希表中所有的 keyhvals 集合名查看哈希表中所有的 valuehlen 集合名获取哈希表中 key 的数量
- 改
hincrby 集合 键 增值hincrbyfloat ……
- 删
hdel 集合名 键1 键2 ……删除集合中,指定个键值对
redis 127.0.0.1:6379> HMSET runoob field1 "Hello" field2 "World"
"OK"
redis 127.0.0.1:6379> HGET runoob field1
"Hello"
redis 127.0.0.1:6379> HGET runoob field2
"World"
redis 127.0.0.1:6379> DEL runoob
(integer) 1高级数据结构
消息队列 Stream
[!quote] 消息队列 Stream 消息队列 Stream 是持久化的消息队列系统【
即使在消息发布的时候,订阅者没有在线,他们也能在后来获取到这个消息】
- 消费组:一个消费组中有多个消费者
- 游标:记录了消费组读取消息队列的位置
- pending_ids:这个数组里记录了消费组已经读取了,但是消费者未确认的消息
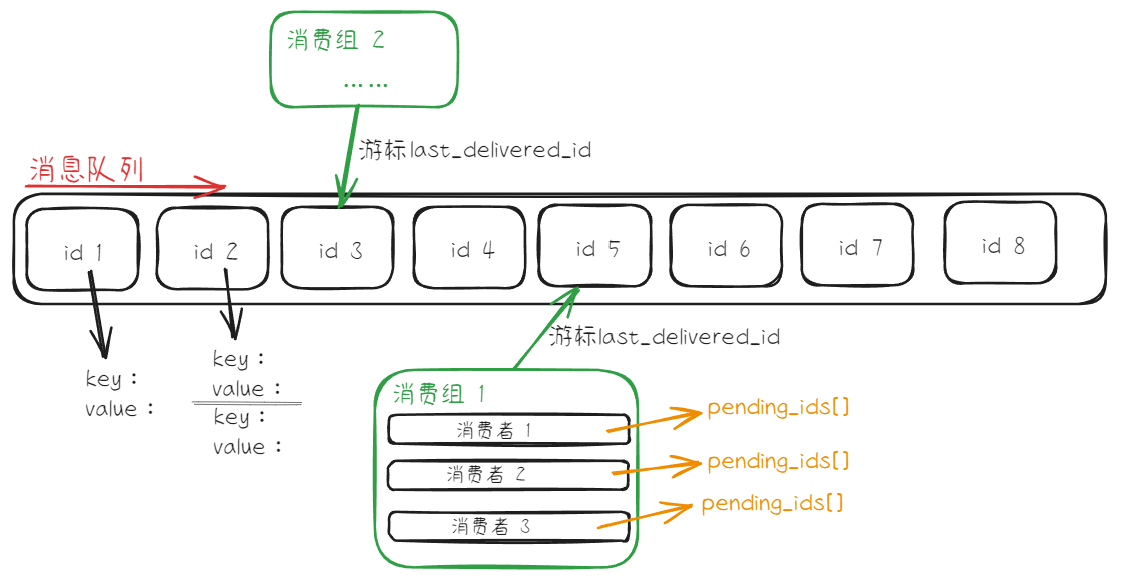
- 消息队列命令
- 添加
XADD 队列名 消息id 键1 值 键2 值 ……添加消息到末尾,如果指定的队列 key 不存在,则创建一个队列,消息 id 设置为*,表示自动设置 id
- 获取
XLEN获取消息长度XRANGE 队列名 开始索引 结束索引 [数量]获取消息列表XREVRANGE 队列名 结束索引 开始索引 [数量]反向获取消息列表XREAD [count 数字] [block 阻塞时间] streams 队列名1 队列名2 队列1的开始索引消息id 队列2的开始索引消息id……以阻塞,或非阻塞方式,获取指定条队列中的指定条消息【不会更新游标,只是简单地读取】
- 删除
XTRIM 队列名 maxlen 数字限制队列的长度,超过设定的数量,旧消息会被删除XDEL 队列名 消息id1 消息id2 ……删除消息
- 添加
[! warning] 添加消息时,如果手动指定 id,要确保 id 是递增的
[!quote] 阻塞,非阻塞
- 非阻塞方式:运行命令后
- 如果 Stream 中有新的消息,会立即返回这些消息
- 如果没有新的消息,会立即返回一个空列表,则程序可以去执行其他任务
- 阻塞方式:运行命令后
- 如果 Stream 中有新的消息,会立即返回这些消息
- 如果没有新的消息,命令就会等待,直到有新的消息,或达到你设定的超时时间,程序会一直在这里等
redis> XADD mystream * name Sara surname OConnor
"1601372323627-0"
redis> XLEN mystream
(integer) 1
redis> XRANGE mystream - +
1) 1) "1713754157907-0"
2) 1) "name"
2) "Sara"
3) "surname"
4) "OConnor"
127.0.0.1:6379> XTRIM mystream MAXLEN 2
(integer) 0
# 从 `mystream` 和 `writers` 这两个 Streams 中读取头部的两条消息,0-0是特殊id,表示头部
127.0.0.1:6379> XREAD COUNT 2 STREAMS mystream writers 0-0 0-0- 消费组命令
- 添加
XGROUP CREATE 队列名 组名 游标创建消费者组xgroup createconsumer 队列名 组名 消费者名将消费者添加到某个消费组
- 获取
XINFO查看流和消费者组的相关信息XINFO GROUPS 消费组打印消费者组的信息XINFO STREAM打印流信息XREADGROUP GROUP 消费组名 消费者名 [count 数字] [block 时间] streams 队列名 …… 消息id ……用于消费者垄断读取消费者组中的消息【该消费组中的其他消费者将看不到此消息】,>表示还未到的最新一条消息【会更新消费组中的游标】
- 删除
XGROUP DELCONSUMER删除消费者XGROUP DESTROY删除消费者组
XACK将消息标记为 " 已处理 "XGROUP SETID为消费者组设置新的最后递送消息 IDXPENDING显示待处理消息的相关信息XCLAIM转移消息的归属权
- 添加
# 从头开始消费
XGROUP CREATE mystream consumer-group-name 0-0
# 从尾部开始消费
XGROUP CREATE mystream consumer-group-name $
# 从 `mystream` 队列的最新位置开始,读取一条消息,将消息分配给名为 `consumer-group-name` 的消费者组中名为 `consumer-name` 的消费者
XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >地理空间 Geo
- 添加
geoadd 键 经度 纬度 位置名称 ……添加地理位置的坐标,将一个/多个经度longitude,纬度latitude,位置名称member,添加到指定的 key 中
- 获取
geodist 键 位置1 位置2计算两个位置之间的距离georadius 键 经度 纬度 搜索半径 半径单位根据用户给定的经纬度坐标来获取指定范围内的地理位置集合georadiusbymember 键 位置名称 搜索半径 半径单位根据储存在位置集合里面的某个地点为中心,获取指定范围内的地理位置集合geopos 键 位置名称1 位置名称2 ……获取地理位置的坐标。用于从给定的 key 里返回所有指定名称的位置geohash 键 位置名称1 位置名称2 ……返回一个/多个位置对象的 geohash 值
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEODIST Sicily Palermo Catania
"166274.1516"
# 搜索存储在 `Sicily` 下,距离经纬度坐标 (15, 37) 在 100 千米以内的成员
redis> GEORADIUS Sicily 15 37 100 km
1) "Catania"
redis> GEOPOS Sicily Palermo Catania NonExisting
1) 1) "13.36138933897018433"
2) "38.11555639549629859"
2) 1) "15.08726745843887329"
2) "37.50266842333162032"
3) (nil)
redis> GEOHASH Sicily Palermo Catania
1) "sqc8b49rny0"
2) "sqdtr74hyu0"HyperLogLog
[!quote] HyperLogLog
HyperLogLog 是用来做基数估计的算法
优点:
- 无论输入元素的数量有多大,它所需的存储空间总是固定的,且非常小
- 虽然有误差,但是可以精确地估计自己的误差【
我们可以知道自己的估计结果有多准确】缺点:
- 只会根据输入元素来计算基数,而不会储存输入元素本身
[!quote] 基数
基数 就是一个数据集中不重复的元素,比如有一个数据集 {1, 3, 5, 7, 5, 7, 8},那么这个数据集的基数集就为 {1, 3, 5 ,7, 8},基数为 5
[!quote] 基数估计 基数估计 就是在误差可接受的范围内,快速计算基数
[!hint] 每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数
pfadd 键 元素1 元素2 ……添加指定元素到 HyperLogLog 中pfcount 键返回指定 HyperLogLog 的基数估算值pfmerge 新键 键1 键2 ……将多个 HyperLogLog 合并为一个 HyperLogLog
# 例子
redis 127.0.0.1:6379> PFADD runoobkey "redis"
1) (integer) 1
redis 127.0.0.1:6379> PFADD runoobkey "mongodb"
1) (integer) 1
redis 127.0.0.1:6379> PFADD runoobkey "mysql"
1) (integer) 1
redis 127.0.0.1:6379> PFCOUNT runoobkey
(integer) 3位图 Bitmap
[!quote] 位图 位图 就是字符串,只不过这个字符串是二进制形式的,这样我们可以更加省内存地记录 bool 类型的值【
按照 String 可以存储 512 MB 来算,如果要记录一个用户一年的签到次数,正常来说需要 365 个键值对,而只用使用一个位图,就可以记录 2^32 次的签到次数】
SETBIT 键 索引 值设置位图中某一位的值【SETBIT 键 7 1将对应的位图的第 7 位设置为 1】GETBIT 键 索引获取位图中某一位的值【GETBIT 键 7获取对应的位图的第 7 位的值bitcount 键统计位图中 1 的个数bitpos 键 0/1返回位图中第一个出现 0/1 位置的索引
setbit bitmap 0 1
getbit bitmap 0
(integer) 1[!hint] 由于位图也是 String,所以可以使用
set来位图
# 1的ASCII码为01100001,0的ASCII码为01100000
set bitmap "11110000"
getbit bitmap 1
(integer) 1
getbit bitmap 2
(integer) 1
GETBIT bitmap 3
(integer) 1
bitcount bitmap
(integer) 20# \xF0 表示 11110000
set bitmap "\xF0"
bitcount bitmap
(integer) 4
bitpos bitmap 0
(integer) 4位域 Bitfield
[!quote] 位域 位域 就是把位图分成多个小的整体,每个整体有多个位
bitfield 键 set 占用的位数 #第几个部分 值设置位域位于哪个部分,和位域占用的位数,和值bitfield 键 incrby 占用的位数 #第几个部分 增加的值对位域进行增值bitfield 键 get u8 #0获取位域的值
# 设置key为player,u8表示占用8位且是无符号整数,#0 表示第1个部分,3是值
BITFIELD player set u8 #0 3
BITFIELD player get u8 #0
1) "3"
# 用字符串的方式查看
GET player
"\x03"布隆过滤器 Bloom Filter
[!quote] 布隆过滤器 布隆过滤器 用于检索一个元素是否在一个集合中
- 【优点】
- 空间效率,和查询时间都比一般的算法要好的多
- 【缺点】
- 有一定的误识别率,而且删除困难 :如果布隆过滤器说某个元素不存在,那它一定不存在;如果说这个元素存在,那这个元素可能不存在
- 一旦元素被添加到布隆过滤器,就无法从过滤器中删除它,
因为删除会影响其他元素的判断
【布隆过滤器的原理】:
- 组成 :布隆过滤器 是一个位数组【
初始状态全为 0】,和多个哈希函数的组合,这两者都是预先设定的 - 添加元素的步骤:
- 当要添加一个元素时,多个哈希函数会为各自为这个元素生成一个哈希值。~~比如添加元素 A ,那三个哈希函数会生成 5, 13, 27 ~~
- 然后位数组根据哈希值将对应位,置为 1。
比如位数组会将 5,13,27 位都设置为 1
- 查询元素步骤 :
- 对于要查询的元素,同样根据多个哈希函数各自生成哈希值
- 然后查看生成的哈希值的位数上是否都是 1
- 如果位数都是 1,则这个元素可能在集合中【
因为输入参数是无限的,哈希值是有限的,所以可能会有其他元素把这些位设为了 1】 - 如果位数有一个不是 1,则这个元素肯定不在集合中
- 如果位数都是 1,则这个元素可能在集合中【