2-3 awk
AWK 是一种优良的文本处理工具,Linux 及 Unix 环境中现有的功能最强大的数据处理引擎之一。其名称得自于它的创始人 Alfred Aho(阿尔佛雷德·艾侯)、Peter Jay Weinberger(彼得·温伯格)和 Brian Wilson Kernighan(布莱恩·柯林汉) 姓氏的首个字母 AWK,三位创建者已将它正式定义为“样式扫描和处理语言”。它允许你创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。最简单地说,AWK 是一种用于处理文本的编程语言工具。
在大多数 Linux 发行版上面,实际我们使用的是 gawk(GNU awk,awk 的 GNU 版本),在我们的环境中 ubuntu 上,默认提供的是 mawk,不过我们通常可以直接使用 awk 命令(awk 语言的解释器),因为系统已经为我们创建好了 awk 指向 mawk 的符号链接。
ll /usr/bin/awk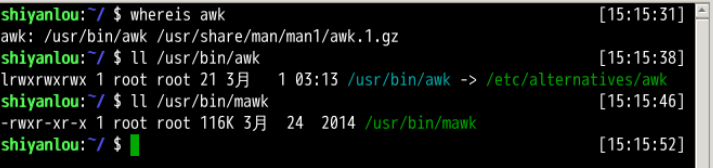
nawk: 在 20 世纪 80 年代中期,对 awk 语言进行了更新,并不同程度地使用一种称为 nawk(new awk) 的增强版本对其进行了替换。许多系统中仍然存在着旧的 awk 解释器,但通常将其安装为 oawk (old awk) 命令,而 nawk 解释器则安装为主要的 awk 命令,也可以使用 nawk 命令。Dr. Kernighan 仍然在对 nawk 进行维护,与 gawk 一样,它也是开放源代码的,并且可以免费获得;
gawk: 是 GNU Project 的 awk 解释器的开放源代码实现。尽管早期的 GAWK 发行版是旧的 AWK 的替代程序,但不断地对其进行了更新,以包含 NAWK 的特性;
mawk 也是 awk 编程语言的一种解释器,mawk 遵循 POSIX 1003.2 (草案 11.3)定义的 AWK 语言,包含了一些没有在 AWK 手册中提到的特色,同时 mawk 提供一小部分扩展,另外据说 mawk 是实现最快的 awk。
awk 所有的操作都是基于 pattern(模式)—action(动作) 对来完成的,如下面的形式:
pattern {action}你可以看到就如同很多编程语言一样,它将所有的动作操作用一对 {} 花括号包围起来。其中 pattern 通常是表示用于匹配输入的文本的“关系式”或“正则表达式”,action 则是表示匹配后将执行的动作。在一个完整 awk 操作中,这两者可以只有其中一个,如果没有 pattern 则默认匹配输入的全部文本,如果没有 action 则默认为打印匹配内容到屏幕。
awk 处理文本的方式,是将文本分割成一些“字段”,然后再对这些字段进行处理,默认情况下,awk 以空格作为一个字段的分割符,不过这不是固定的,你可以任意指定分隔符,下面将告诉你如何做到这一点。
awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]其中 -F 参数用于预先指定前面提到的字段分隔符(还有其他指定字段的方式),-v 用于预先为 awk 程序指定变量,-f 参数用于指定 awk 命令要执行的程序文件,或者在不加 -f 参数的情况下直接将程序语句放在这里,最后为 awk 需要处理的文本输入,且可以同时输入多个文本文件。现在我们还是直接来具体体验一下吧。
先用 vim 新建一个文本文档:
vim test包含如下内容:
I like linux
www.shiyanlou.com- 使用 awk 将文本内容打印到终端:
# "quote>" 不用输入
awk '{
quote> print
quote> }' test
# 或者写到一行
awk '{print}' test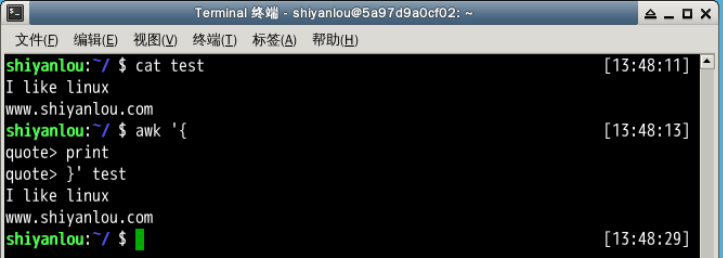
说明: 在这个操作中我是省略了 pattern,所以 awk 会默认匹配输入文本的全部内容,然后在 {} 花括号中执行动作,即 print 打印所有匹配项,这里是全部文本内容。
- 将 test 的第一行的每个字段单独显示为一行:
$ awk '{
> if(NR==1){
> print $1 "\n" $2 "\n" $3
> } else {
> print}
> }' test
# 或者
$ awk '{
> if(NR==1){
> OFS="\n"
> print $1, $2, $3
> } else {
> print}
> }' test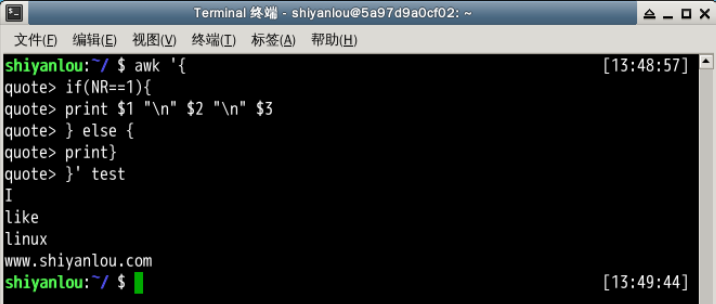
说明: 你首先应该注意的是,这里我使用了 awk 语言的分支选择语句 if,它的使用和很多高级语言如 C/C++ 语言基本一致,如果你有这些语言的基础,这里将很好理解。另一个你需要注意的是 NR 与 OFS,这两个是 awk 内建的变量,NR 表示当前读入的记录数,你可以简单的理解为当前处理的行数,OFS 表示输出时的字段分隔符,默认为 " " 空格,如上图所见,我们将字段分隔符设置为 换行符,所以第一行原本以空格为字段分隔的内容就分别输出到单独一行了。然后是 $N 其中 N 为相应的字段号,这也是 awk 的内建变量,它表示引用相应的字段,因为我们这里第一行只有三个字段,所以只引用到了 $3。除此之外另一个这里没有出现的 $0,它表示引用当前记录(当前行)的全部内容。
- 将 test 的第二行的以点为分段的字段换成以空格为分隔:
awk -F'.' '{
> if(NR==2){
> print $1 "\t" $2 "\t" $3
> }}' test
# 或者
awk '
> BEGIN{
> FS="."
> OFS="\t" # 如果写为一行,两个动作语句之间应该以";"号分开
> }{
> if(NR==2){
> print $1, $2, $3
> }}' test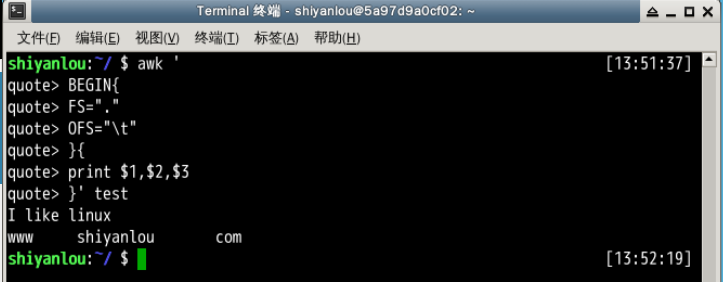
说明:这里的 -F 参数,前面已经介绍过,它是用来预先指定待处理记录的字段分隔符。我们需要注意的是除了指定 OFS 我们还可以在 print 语句中直接打印特殊符号如这里的 ,print 打印的非变量内容都需要用 "" 一对引号包围起来。上面另一个版本,展示了实现预先指定变量分隔符的另一种方式,即使用 BEGIN,就这个表达式指示了,其后的动作将在所有动作之前执行,这里是 FS 赋值了新的 . 点号代替默认的空格。
注意: 首先说明一点,我们在学习和使用 awk 的时候应该尽可能将其作为一门程序语言来理解,这样将会使你学习起来更容易,所以初学阶段在练习 awk 时应该尽量按照我那样的方式分多行按照一般程序语言的换行和缩进来输入,而不是全部写到一行(当然这在你熟练了之后是没有任何问题的)。
| 变量名 | 说明 |
|---|---|
FILENAME | 当前输入文件名,若有多个文件,则只表示第一个。如果输入是来自标准输入,则为空字符串 |
$0 | 当前记录的内容 |
$N | N 表示字段号,最大值为 NF 变量的值 |
FS | 字段分隔符,由正则表达式表示,默认为空格 |
RS | 输入记录分隔符,默认为 ,即一行为一个记录 |
NF | 当前记录字段数 |
NR | 已经读入的记录数 |
FNR | 当前输入文件的记录数,请注意它与 NR 的区别 |
OFS | 输出字段分隔符,默认为空格 |
ORS | 输出记录分隔符,默认为 |
关于 awk 的内容本课程将只会包含这些内容,如果你想了解更多,请期待后续课程,或者参看一下链接内容: